关于数据挖掘的一些知识,内容包括分类,聚类,异常值检测,关联性分析等等。
大量截图和思路来自 the University of Queensland 的Dr Hongzhi Yin所教课程INFS7203 Data Mining。
I. Classification 分类
1.模型评估(model evluation)
混淆矩阵(confusion matrix)
| Prediction/actual | T | F |
|---|---|---|
| T | True positive(TP) | False positive(FP) |
| F | False negative(FN) | True negative(TN) |
课件中的ppt:真实值是行,预测值是列。
在我上网查资料或者很多流行的混淆矩阵的包里面都是我上述的真实值是列, 预测值是行。当时就默认是课件里的情况,所以在计算中会出现问题,并且经常有想要验算的想法。所以这里用和课件中想反的情况,提醒大家这都是取决于自己的。
评估方法
$Accuracy = $
很直观,预测成功的数量除以预测的总数
但是有
一个几个不好的地方。我们很多时候只关注T和F中的一个。\(Precision = \frac {TP}{TP + FP}\)
\(Recall = \frac{TP}{TP+FN}\)
\(F1-value = 2\frac{Precision*Recall}{Rrecision+recall}\)
最爱的举例环节:
小明有一天终于进入了心心念念的相亲角(有100个女生等着他)。由男人的三大错觉(分类器)他觉得自己玉树临风,风趣幽默,才华横溢, 预测会被99个女生有好感,1一个没有好感,然而事实是如此的残酷,相亲是如此的激烈,真实情况100个女生都没有相中小明。于是我们产生了一个混淆矩阵:
| Prediction/actual | T | F | Total prediction |
|---|---|---|---|
| T | 0 | 99 | 99 |
| F | 0 | 1 | 1 |
| Total actual | 0 | 100 |
我们可以算出\(accuracy = \frac{1}{100} = 0.01\), 果然“男人的自我感觉”这个分类器非常的糟糕。
小明在这次无情的现实打脸后,强迫着被爸妈再次带到了相亲角。根据上次的经验,卑微的小明这次也觉得没有人会看上他,预测没有女生相中自己。然而这次事实上有一个女生不知道是不是圣母爆发,觉得小明太卑微了,给了他一次机会。 于是我们产生了一个混淆矩阵:
| Prediction/actual | T | F | Total prediction |
|---|---|---|---|
| T | 0 | 0 | 0 |
| F | 1 | 99 | 100 |
| Total actual | 1 | 99 |
这次\(accuracy = \frac {99}{100} = 0.99\)。 哇喔,小明顿时好佩服自己,居然有\(99%\)的预测成功率预测成功自己不会被人看上。 等等,为什么预测重心变成了自己不成功的概率了,不是应该更希望自己被相中的嘛,让不成功的概率这么高干嘛🤣。
3年后,小明终于走出了上一次相亲的阴影(等新的女生刷新太不容易了),再次走进相亲角。经过了人生的沉淀,小明明白他不需要关注那些看不上自己的女人(气急败坏), 而要把重点放在那些看上自己的女生们。这次小明预测自己有20个女生对他有好感,80个没有。事实情况是有10个女生看中小明,90个没有。更重要的是撞大运了,那10个女生刚好也是小明预测应该喜欢他的。于是我们又有了混淆矩阵:
| Prediction/actual | T | F | Total prediction |
|---|---|---|---|
| T | 10 | 10 | 20 |
| F | 0 | 80 | 80 |
| Total actual | 10 | 9 |
此时\(accuracy = \frac{10+80}{100} = 0.9\),当然这也充其量只能证明小明对自己有比较清醒的认知(丑) ,和他的目标(脱单)没什么关系的。 但是三年中小明学会了第二种度量方法\(Precesion = \frac{10}{10+10}=0.5\), 这说明小明以后预测谁谁谁喜欢自己,都能有50%的成功率!(卧槽,为什么要高兴,本来不就是成功和失败2个选项吗??)。
\(Recall = \frac {10}{0+10} = 100\%\), 这说明喜欢小明的妹子100%都被小明预测中了(呵,女人)。
现在的小明要是回到了三年前,他预测有99个妹子喜欢他,就会有45个妹子真的喜欢(Precision=0.5),而且小明对她们索然无味,都没有出乎他意料外的妹子(recall = 1)。小明想:我果然还是那个我,玉树临风,风趣幽默,才华横溢。醒醒现在的你已经不会说这样的话了,因为你已经是一个成熟的分类器(Classification)了。
总结
如果嫌上面的例子篇幅过大,直接到PPT的week2-P43 背公式。
应付完了考试后,如果想加深理解,为什么要有新的度量方式而不是很容易理解的accuracy,可以google或者复习小明的悲惨经历。
上述的遭遇也是这一章Classification 分类的一个具体演示。小明基于他的数据(身高体重颜值兴趣背景等)有了一个对自己的认知(分类器)。当小明经过了一次相亲角的真实遭遇后(混淆矩阵评估),他验证了自己的认知对不对(这个分类器的好坏)。如果他对自己的认知非常的高,他就知道了他是哪种妹子的菜,他以后看到这种类型的妹子就知道他们很可能发生什么故事。
杠精提问:那你这个认知(分类器)哪里来的啊,你一开始的认知(玉树临风,风趣幽默,才华横溢)不是错的吗?这三年小明是怎么提升自己的啊(怎么改进分类器)?
“承认我优秀那么难吗,下一节就告诉你啦,每天100个俯卧撑100个仰卧起坐…….变秃”
2. 分类方法
1. Rote-learner (最原始最土味)
当你要预测的数据和训练集里有的数据一模一样的时候,预测结果就是训练集中数据的标签。
2. KNN(K近邻)
你先选一个K,比如5
- 你每次要预测一个数据的时候,就找离这个数据最近的5个训练集里面的点。
投票这5个点的分类。哪种分类占的多你预测的这个数据就属于这种分类。
怎么定义距离? 欧几里得距离(误差的平方和开根号)或者公式 \(\boldsymbol{d i s t}=\sqrt{\sum_{\boldsymbol{k}=1}^{\boldsymbol{n}}\left(\boldsymbol{p}_{\boldsymbol{k}}-\boldsymbol{q}_{\boldsymbol{k}}\right)^{2}}\)
p 和 q 是数据,一般我们的数据都是多维的,例如数据:庄笑齐(男,高,富,帅),每一个相同的列相减等到误差,误差平方和,开根号 ——> 距离
KNN的缺点:
如何定义这个k值,如果k很小,我们的判断容易被噪声(noise)影响,如果k太大,可能包含更多其他的分类
KNN需要scale,因为数据的大小值非常影响knn的判断。
举例环节:我们现在的数据集拥有(年龄,收入) 2个属性,和一个标签(职业)
现在我们有2个样本,一位程序员(25,10000)和一位医生(50,15000),现在我们要预测一位30岁拥有14000月薪的人的职业。
取k=1,根据公式\(d(x,程序员)=\sqrt{(25-30)^2+(10000-14000)^2} = 4000\),\(d(x,医生)=\sqrt{(50-30)^2+(15000-14000)^2} = 1000\), 由于距离医生更近,我们判断这人是一位医生。
然而事实上我们觉得他应该是一个程序员,因为更加的年轻。然而年龄在这个距离的公式里贡献的非常小,因为年龄和收入它们的纬度(定义域)不一样,所以在KNN中,我们经常需要预先进行scale操作,保证数据都在同一个度量标准中。
经过scale(根据比例压缩进0到1之间),我们现在的数据是:程序员(0.5,0.66),医生(1,1),
x(0.66.0.93)。(这个scale方法是我瞎XX想当然的)
\(d(x,程序员)=\sqrt{(0.5-0.66)^2+(0.66-0.93)^2} = 0.31\),
\(d(x,医生)=\sqrt{(1-0.66)^2+(1-0.93)^2} = 0.35\),
现在x就被预测为程序员了。
KNN不需要预先训练一个模型(lazy),每次预测一个数据,都要重新计算一边所有数据点的距离去找最近的,时间复杂度很大。
3. Naïve Bayes(朴素贝叶斯)
目标:我们有一组数据A,希望用这一组数据A判断它属于哪个类
核心思路:计算在给定这组数据的情况下它属于各个类的概率,概率最高的就把它判定为这个类。
属于类C的概率就等于:\(P(C|A)\)
我们知道 \(P(C|A)=\frac{P(A|C)P(C)}{P(A)}\)
我们现在有什么:\(P(A_i|C)\):对于类C,每一种属性的概率。P(C):这个类在所有类里面的概率,P(A): 所有的\(P(C_i|A)\)都是一样的,我们只比较大小的,可以忽略掉,比如要比\(\frac{5}{10000}\)和\(\frac{5}{10000}\)的大小不需要关心\(10000\).
缺点:为什么把这个分类方法的缺点提前就是朴素贝叶斯的最大bug,没有这个缺点进行不下去计算。我们怎么能从\(P(A_i|C)\)来得出\(P(A|C)\)呢? 我们知道互相独立的事件的联合概率就等于各自的概率的乘积,所以我们朴素贝叶斯就假设所有属性是独立的???
有了这个假设后,我们的目标就变成了求出
\[\Pi P\left(A_{i} | C_{j}\right) \times P\left(C_{j}\right)\]的最大值。
课件,tutorial,谷歌里的例子都非常的详细,我就不贴了,理解过程就好。
其他缺点:在对连续性变量操作的时候要提前把它们离散化,不然针对一个数据的概率会非常的少,效果也不好。
改进:
当我们做\(\Pi P\left(A_{i} | C_{j}\right) \times P\left(C_{j}\right)\)这一步的时候,经常是很多很小很小的概率(0.0几)相称,值会越来越小,从而可能导致失去精确度(因为计算机算不了小数位很长的值,会四射五入)。
这时候我们就给它们取个\(log\)变成\(\sum \log P\left(A_{i} | C_{j}\right)+\log P\left(C_{j}\right)\).
\(\Pi P\left(A_{i} | C_{j}\right) \times P\left(C_{j}\right)\)如果这个项目里有一项的概率是0,那就全为0了,是不对的。所以我们会加一个特别特别小的值,让概率避免成为0。
例如有一个对于收入的分类,标签为“低”,“中等”,“高”。 但是我们数据集里没有收入为“低”\(\Rightarrow P(C=“低”)=0\).
总共有1000个数据,我们就可以把\(P(C=“低”) = 0+1 / 1003\), 1003是因为在“中等”和“高”里也要加1。
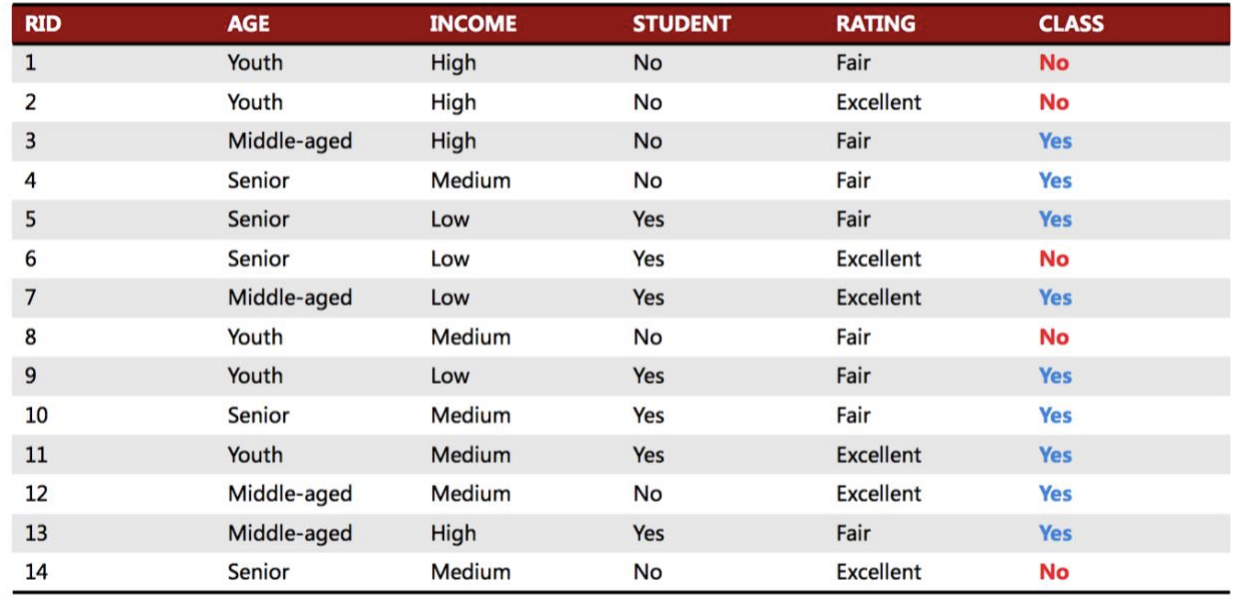
4.决策树
概念
下图是一个决策树的例子
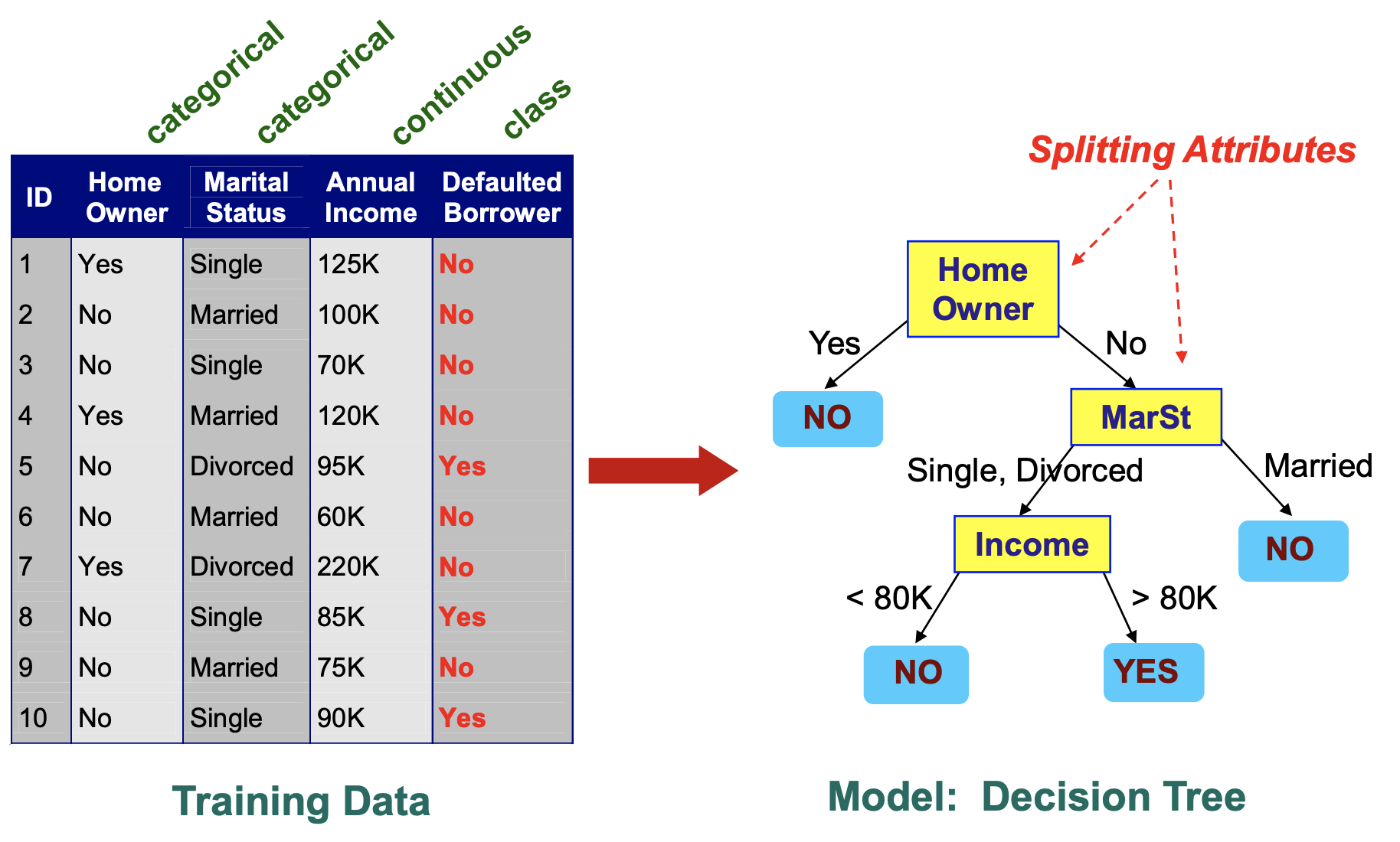
决策树易于理解,就是根据你的输入值一层一层的筛选出最后的Class。
杠精提问:那你是怎么选这个属性(右图黄色部分)作为分割的呀?那分割的条件又是怎么确定的呢?对于连续型的变量(Income),你是怎么找到选取80K作为临界值的呢?又是什么时候结束决策树的呢?(一定要全部的attribute全部分割过后吗?
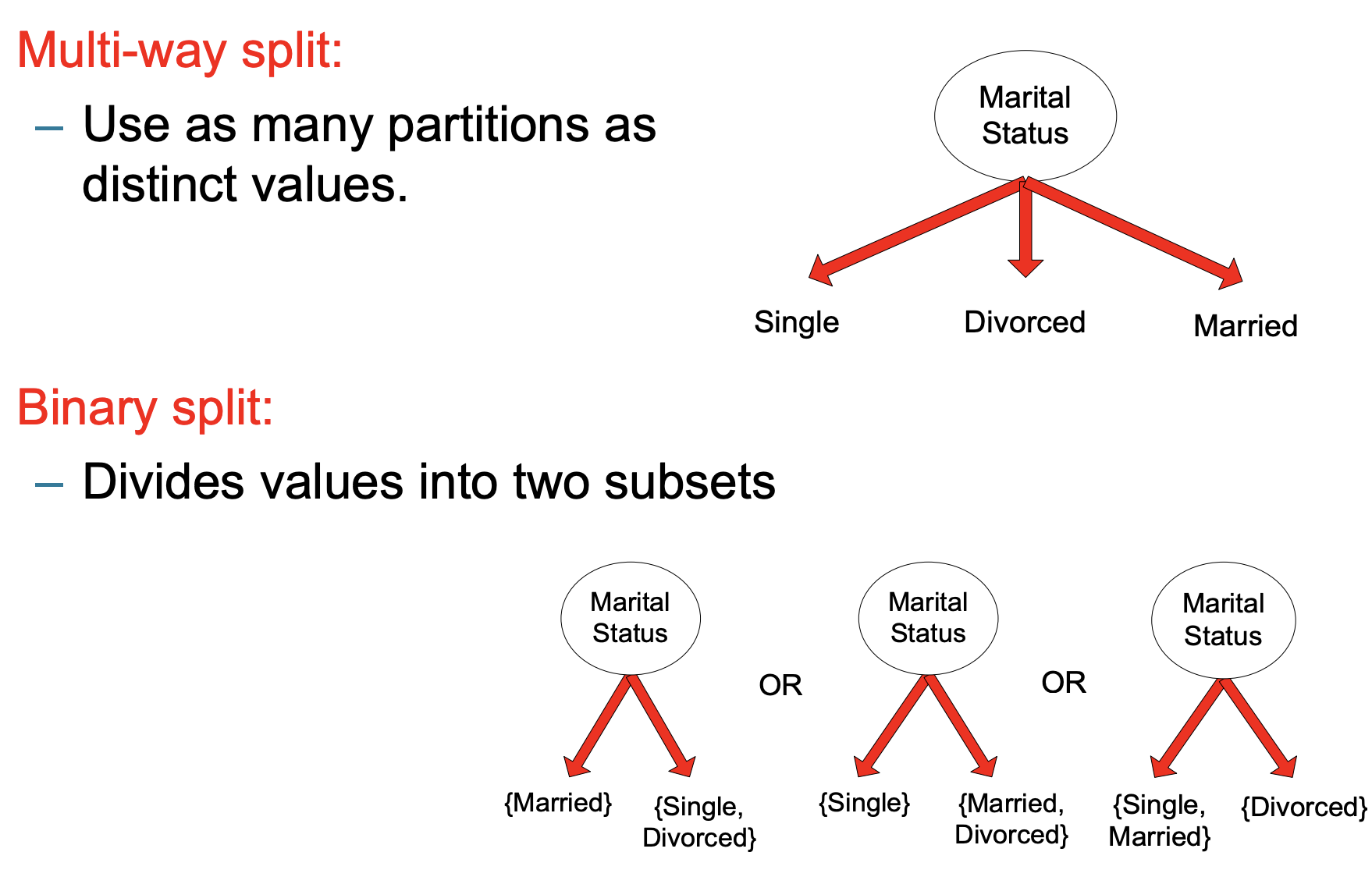
Nominal Attributes:
可以有多维的分割和二元的分割
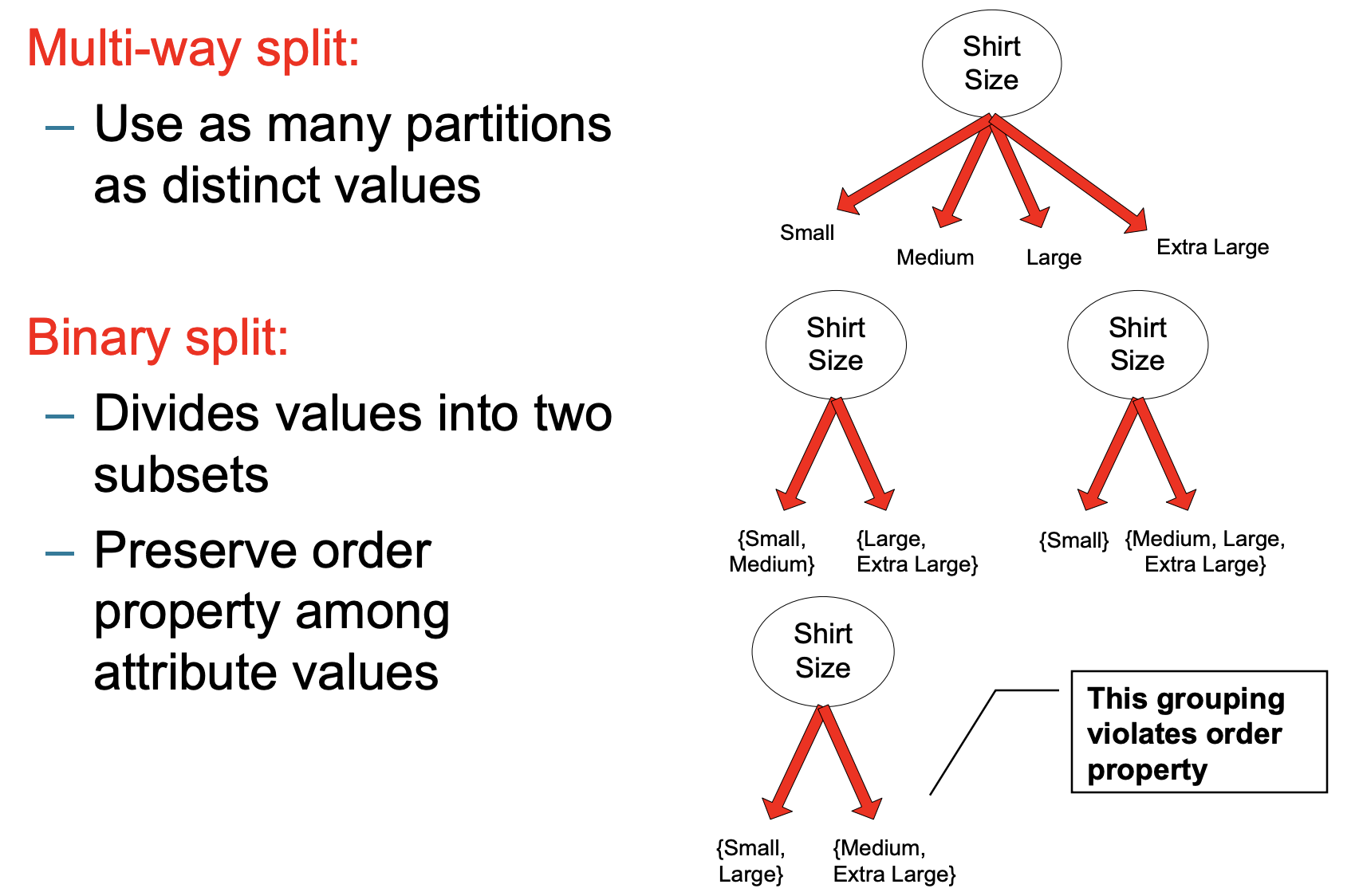
Ordinal Attributes:
多元的形式直接把所有情况分开,而二元的形式必须要注意属性里存在的顺序。
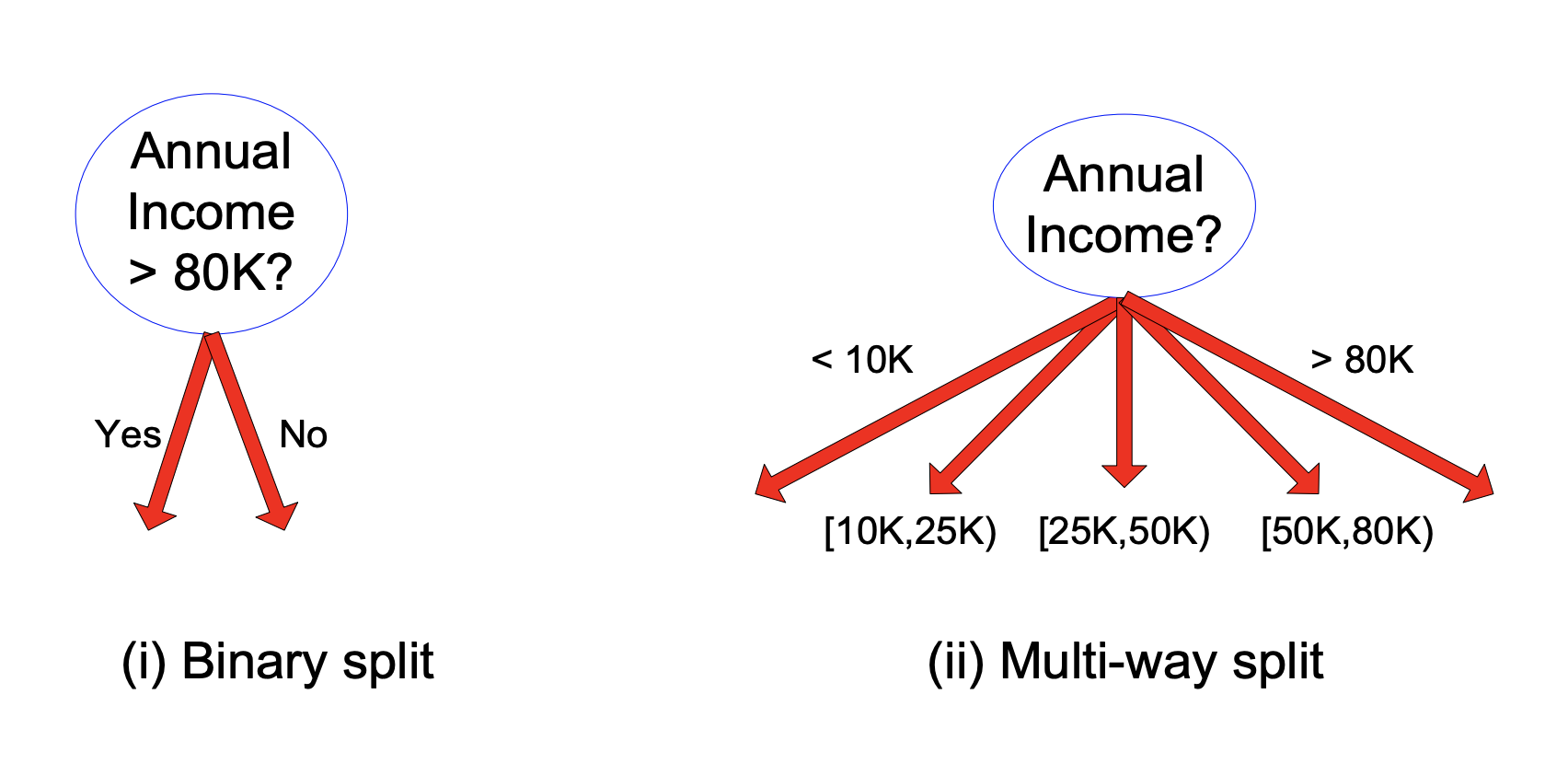
Continuous Attributes
怎么样的分割才算好呢? 如果我们总共有20条记录,用一个分割条件后,各得到10条属性。这十条属性的类都刚好属于它们原来的类,即预测100%,纯净度purity也是100。我们定义一个测量的尺度叫做impurity(不纯度)
由此我们有了3种方法来计算impurity
1. Gini Index
选取一个属性P,计算这个属性的GINI值 GINI(P)
将P分割成多个子节点后,计算每个的GINI值,在各自乘以它们的权重(weights)得到GINI(M)
计算 Gain = GINI(P) -GINI(M)
最高的Gain就是最好的分割
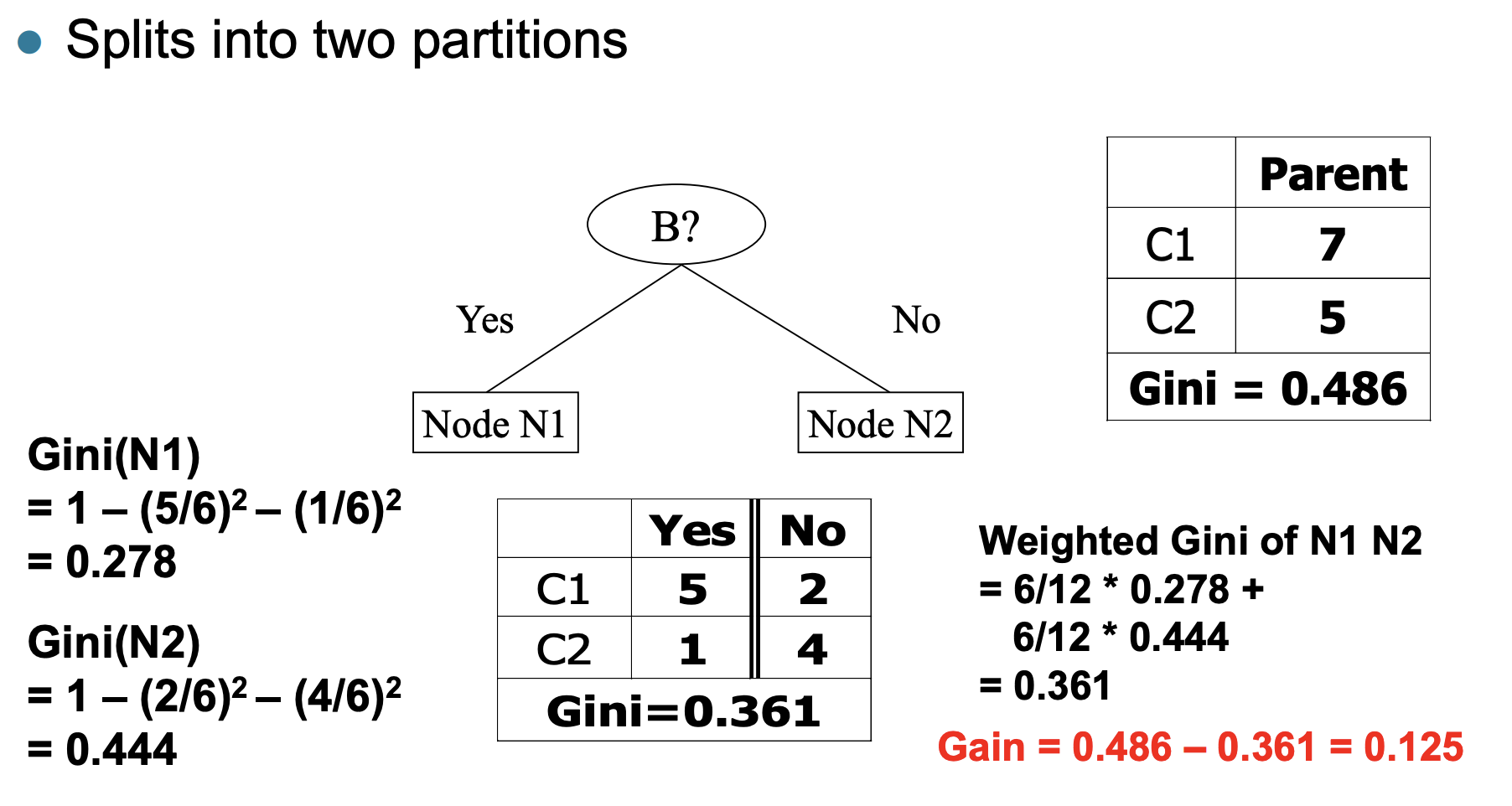
具体例子:
对于二元分类问题的计算
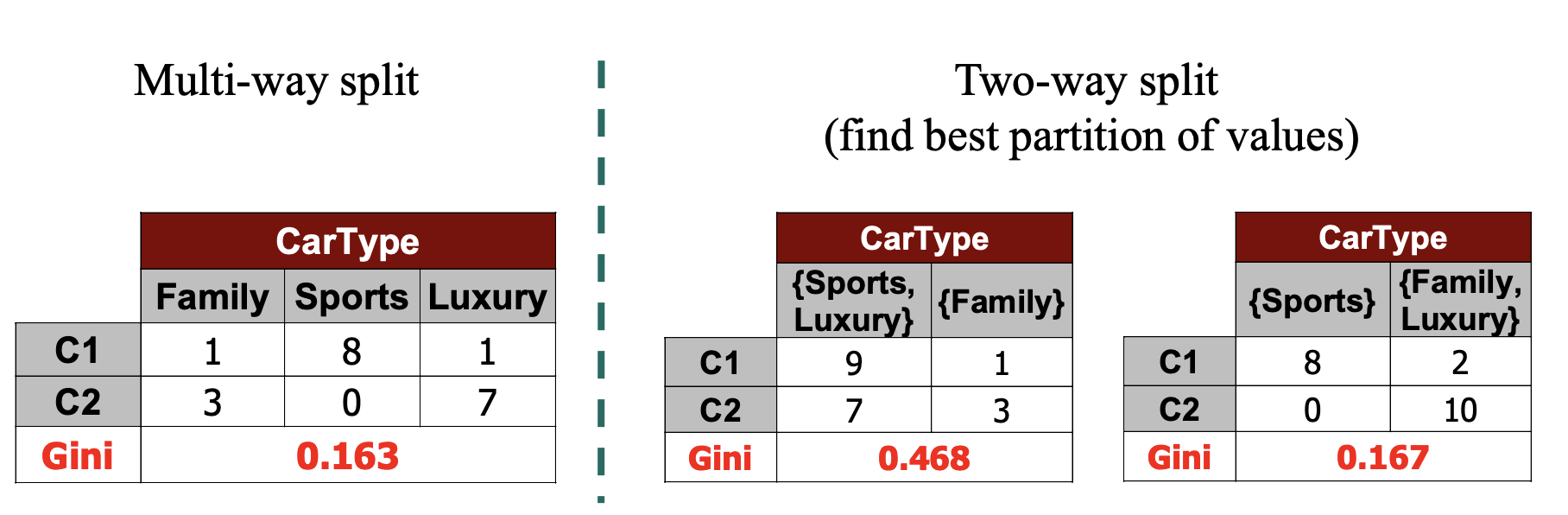
对于多元属性的计算
对于连续型属性的计算
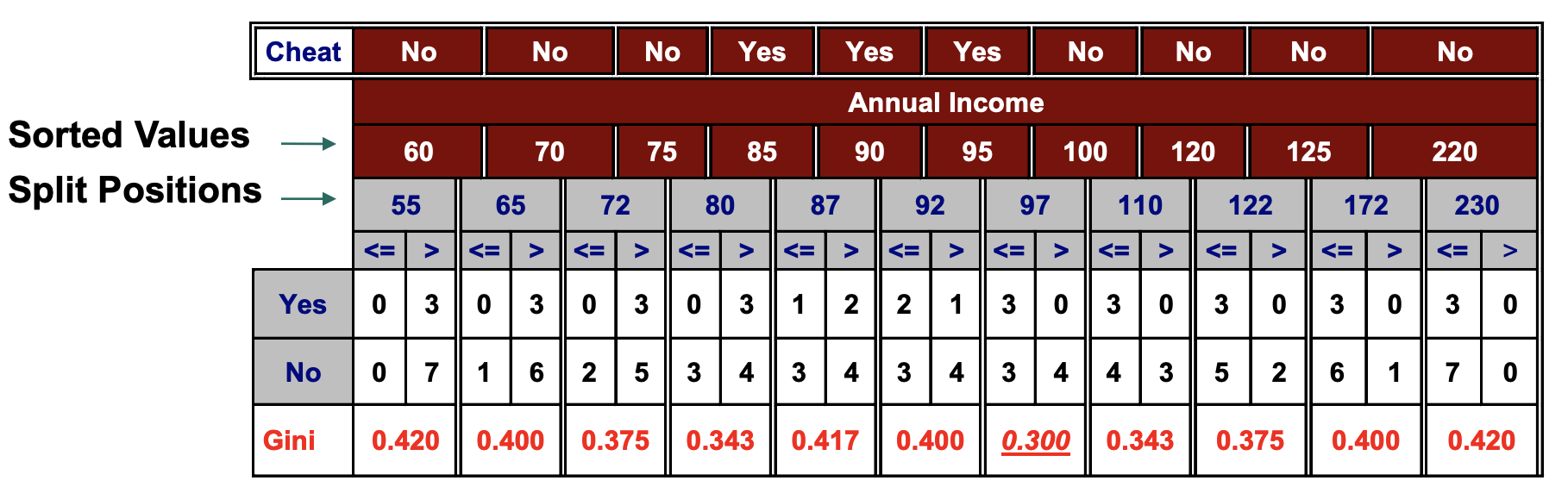
- 将所有的value进行排序(图中的sorted values)
- 将sorted values两两之间计算平均值作为split position(即分割的条件)
- 将问题化为二元分类问题进行GINI INDEX计算
找到最小的GINI的就是最小的impurity
2. Entropy
\(\text { Entropy }(t)=-\sum p(j | t) \log p(j | t)\)
\(\sum p(j | t)\) is the relative frequency of class j at node t.
\(G A I N_{\text {rut }}=\text { Entropy }(p)-\left(\sum_{i=1}^{k} \frac{n_{i}}{n} \text { Entropy }(i)\right)\)
可以看成和GINI INDEX一样,只是计算的公式变了。
然而以上2种方法都有一个问题:Node impurity measures tend to prefer splits that result in large number of partitions, each being small but pure
计算纯净度的方法倾向于有大量分割的属性,例如如果对ID进行计算,它的纯净度就是1因为没有不同的。
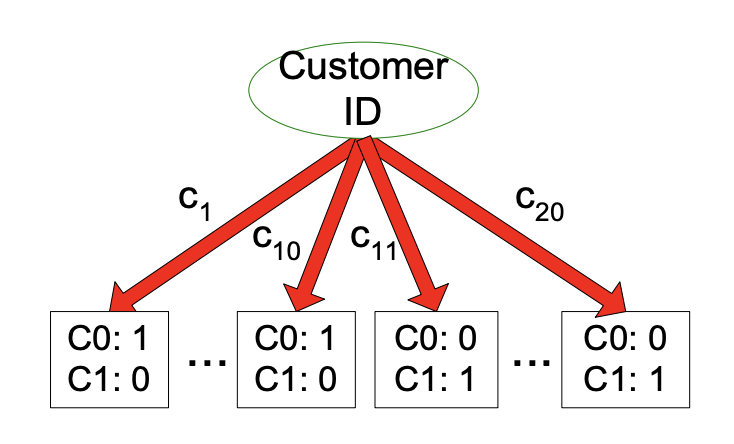
但是这并没有实际意义,如果我们将customer ID分割的话。因此我们有一个新的度量标准:
- 计算\(\text { SplitINFO }=-\sum_{i=1}^{k} \frac{n_{i}}{n} \log \frac{n_{i}}{n}\) 可以当作\(\frac{n_{i}}{n}\)的entropy
- 计算\(\operatorname{Gain} R A T I O_{\text {stat }}=\frac{G A I N_{\text {sut}}}{\text {SplitINFO}}\) , 选GainRATIO最高的
3. Error
\(\text {Error }(t)=1-\max P(i | t)\)
什么时候终止分割?
- 当这个节点只剩下了一种class
- 当这个节点里的tuple都是一样的(无法分割了)
- early termination(提前结束避免过度拟合overfitting)
Overfitting的坏处
- 太多的分支导致noise可能也成为了分割的条件导致错误。
- 对于未知的样本,准确性很差:因为它对于已知数据集的拟合效果太高了。
避免overfitting的方法:
early termination
- 结束当剩余的数据不满足用户自己定于的阈值时
- 结束当在扩展节点后却不提升impurity
优缺点
优点:
- 易于理解,模型的可解释性
- 易于构建
- 得益于已经训练出了模型,做分类十分迅速
- 对noise有鲁棒性(抗噪声,前提是overfitting要做的好)
- 容易处理冗余或无关的属性
缺点:
- 决策树要占据的space要求非常大(使用贪婪算法一般不能够找到最优树)
- 没有考虑属性之间可能存在影响
- 每次只单独使用一个attribute做分割
例题:如何从零开始构建一个数据库
- 计算每个attributes各种分割可能性的GINI,找到最低的GINI值(就是最高的GAIN)(找出分割的条件)
- 比较每个attributes最低的GINI值,找到最低的GINI值,即是第一步的分割属性
- 查看第一步分割后的表格,重复1,2,直到前面提到的决策树终止条件
II.Similarity(相似度)
相似度该怎么度量呢?
对于nominal的,非常简单,非0即1
对于有顺序的ordinal,\(Dissimilarity = |x-y|/(n-1)\) (values mapped to 0 to n-1, n is the number of values).
例如对于收入(low, medium, high), 可以map变成(0,1,2), \(dissimilarity(low, high) = |0-2|/2 = 1\)
对于连续型的随机变量,有3种measure的方法,当含有多个变量时,必须先做normalization(scale)
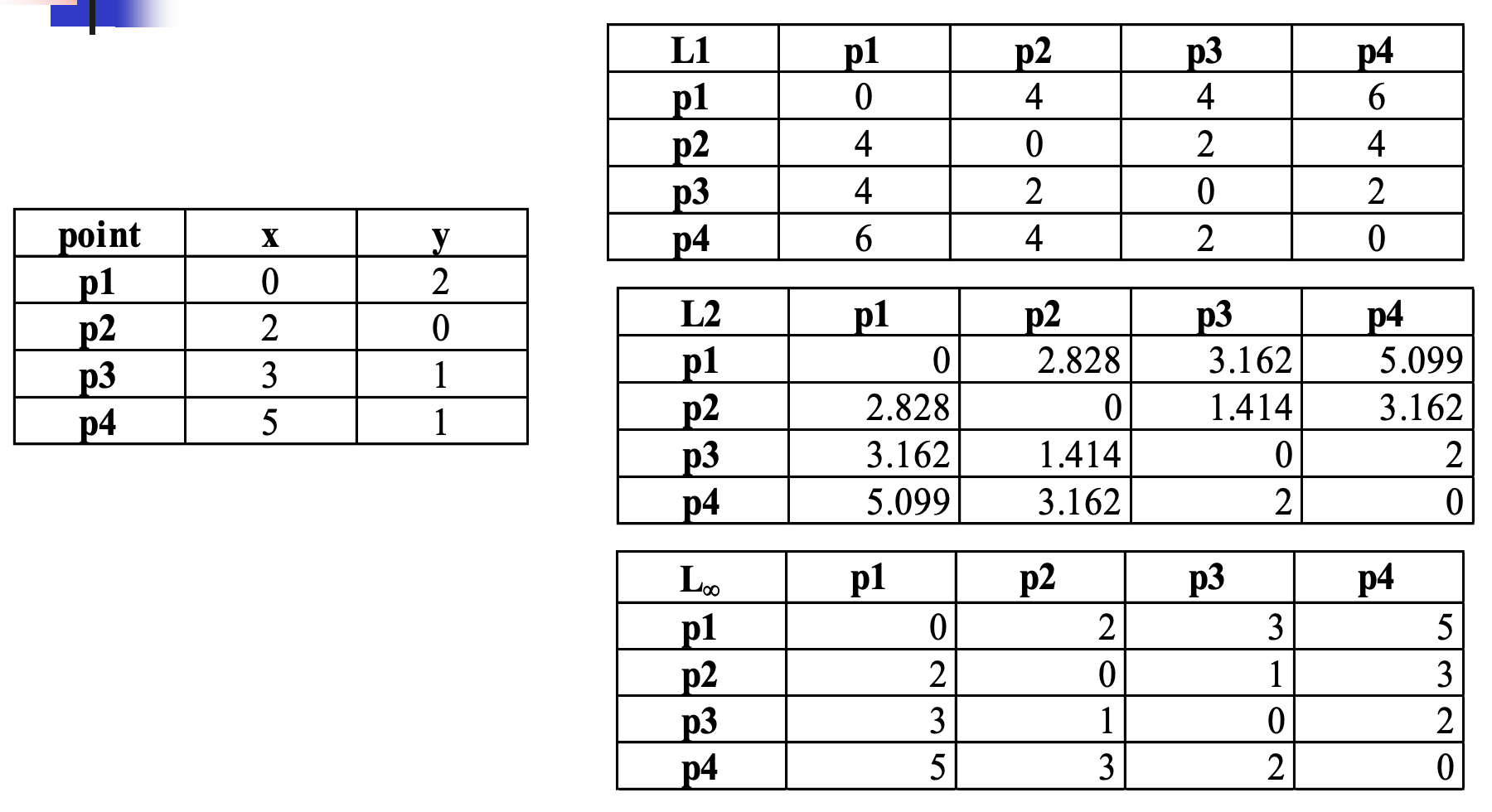
1. 曼哈顿距离(aka "City block”, taxicab, \(L_1\)norm , Manhattan distance)
$ d(x,y) = _{k=1}^{n}| x_k-y_k|$
2. 欧几里得距离(Euclidean distance,aka \(L_2\) norm)
$ d(x,y) = $
3. Supermum(aka \(L_{max}\)norm, \(L_{\infty}\)norm)
\(d(x,y) = max(|x_k -y_k|)\)
例子:
二元属性的相似性

例子:

为什么要用Jaccard,是因为很多时候我们只关注都是1的情况。
例如在一个超市的用户和物品表格中,1表示该用户买了这类物品,0表示没买:
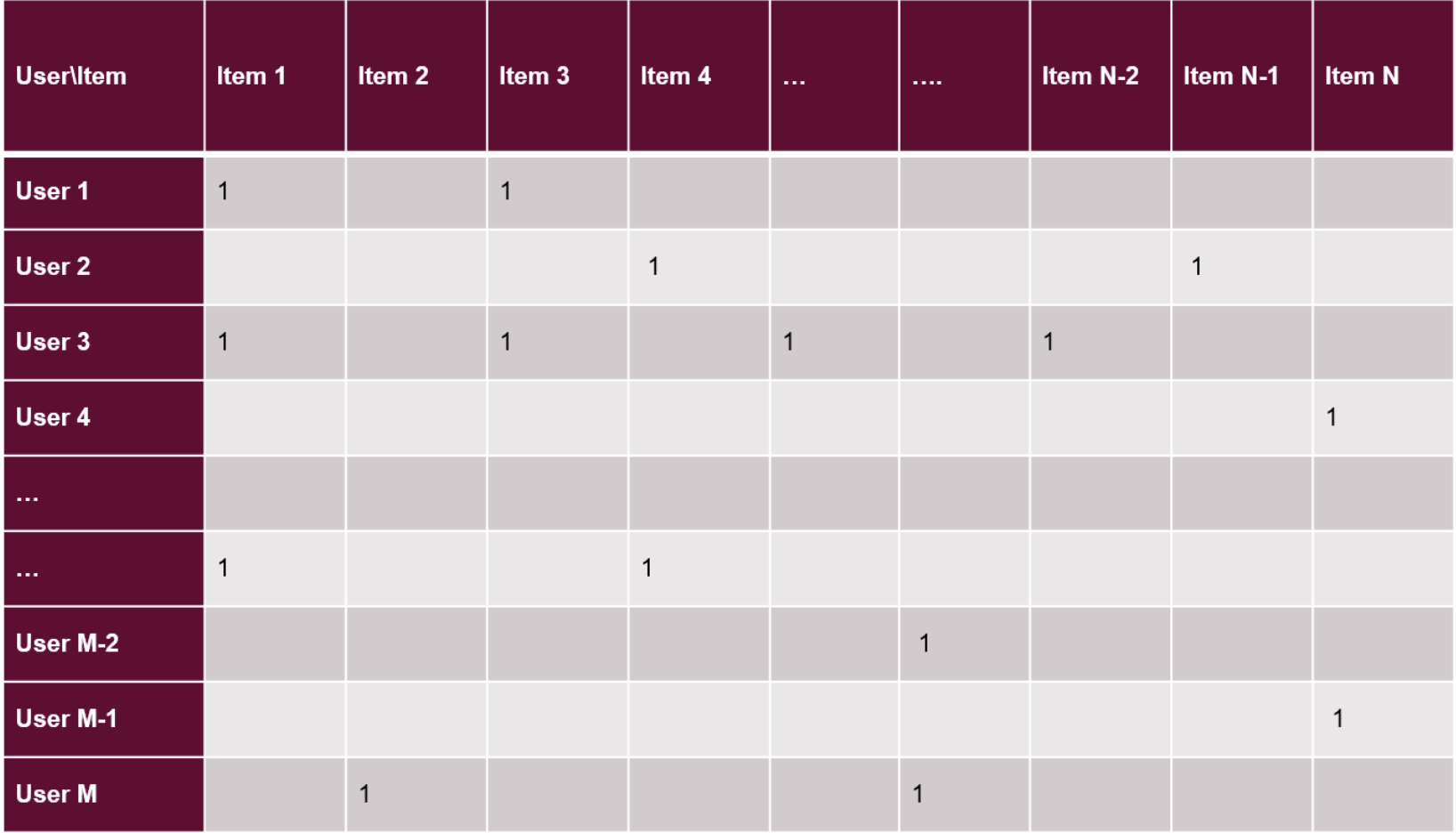
很容易想到,0将会有非常多,1很少,所以使用SMC会给我们错误的信息。
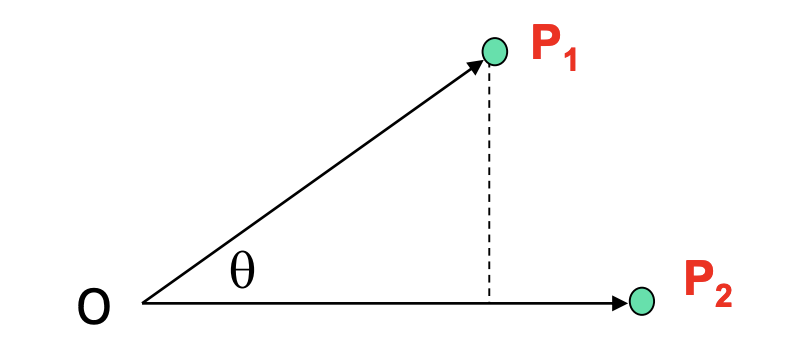
Cosine Similarity
将每一条tuple变成一个向量vector,计算2个向量间的夹角
\(\cos \left(p_{\nu}, p_{2}\right)=\left(p_{t} \bullet p_{2}\right) /\left\|p_{t}\right\|\left\|p_{2}\right\|\)
应用:
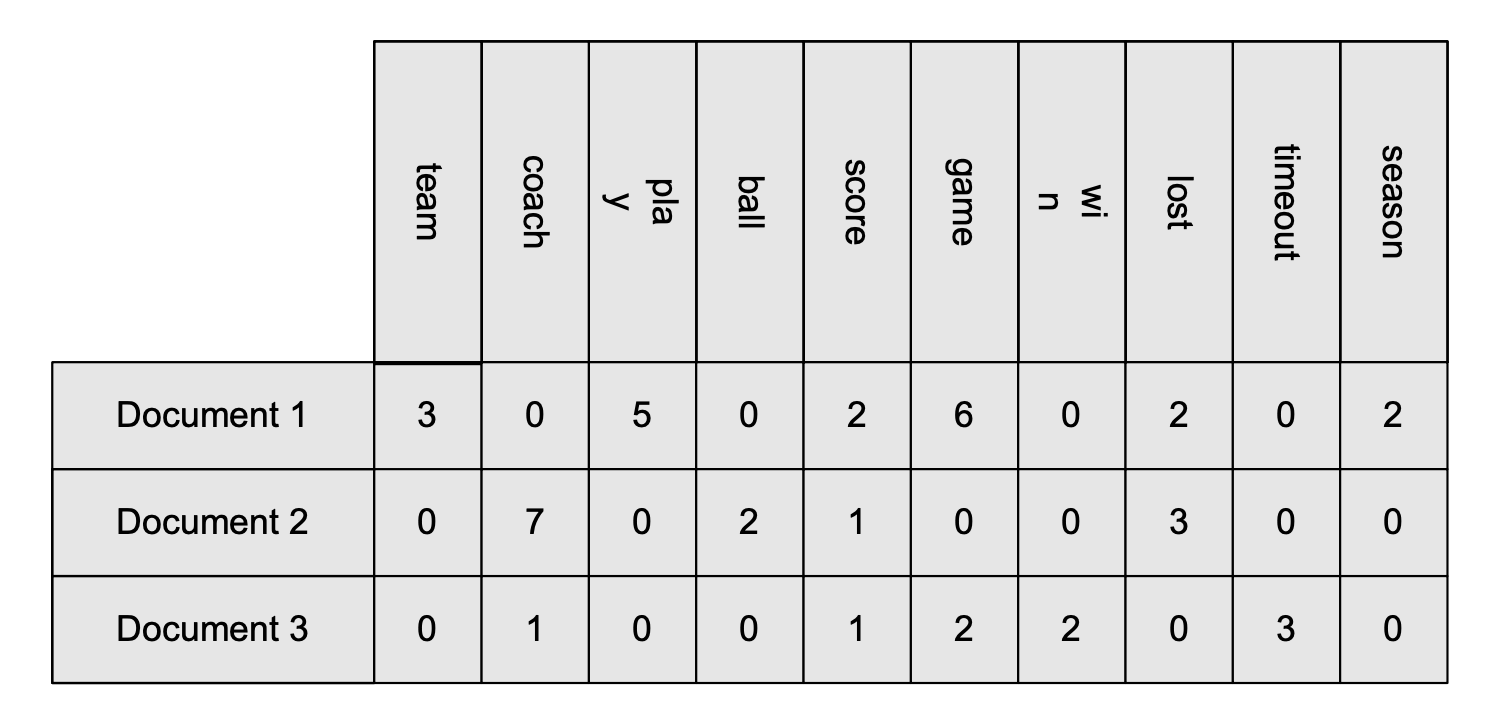
例如我们想查看2个文档是否相似。我们找出几个关键单词在这几个文档中出现的频数。做成上图的表格。
我们计算每个document的cosine similarity就能计算出2个文档间的相似度。
III. Clustering 聚类
1.概念
聚类和分类的区别就是没有标签了。
举例环节:
有很多种聚类的形式:
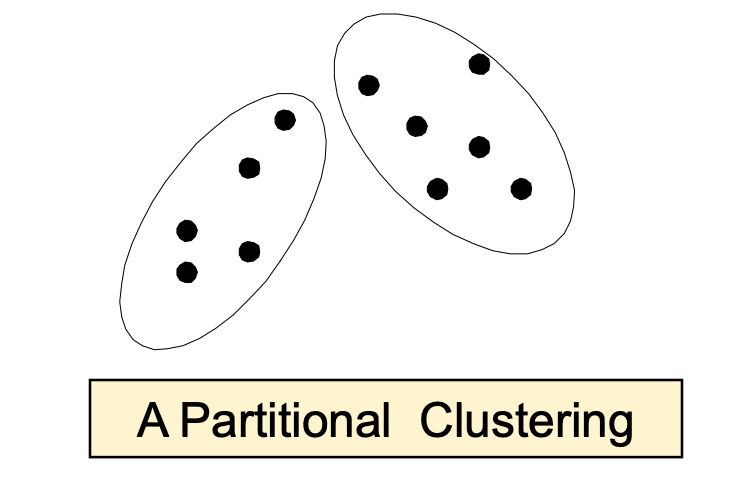
Partitional Clustering(分区聚类):类和类之间是没有交集的。例如常见的k-means。
Hierarchical Clustering(分层聚类):一个类是可以包含其他类的。例如我属于数据科学专业,数据科学专业属于工程学院,工程学院属于大学。
我属于帅哥,帅哥属于男的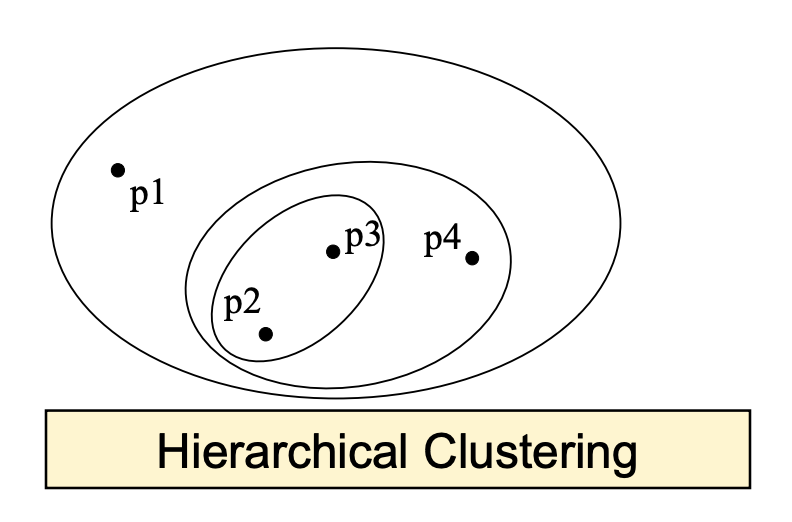
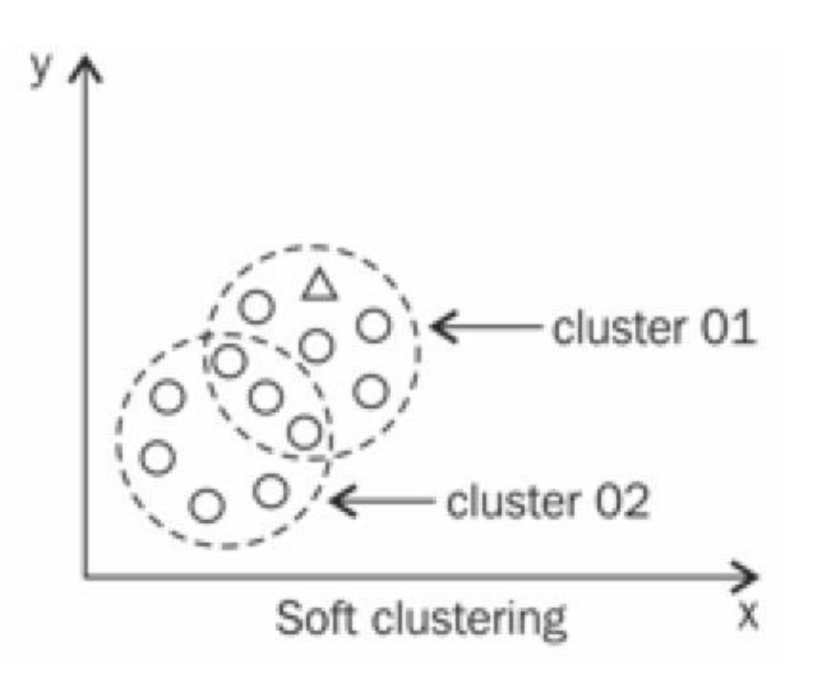
Soft Clustering(软聚类?):一个数据(object)可以属于多个类,和第二种聚类方式的区别在于,类之间有交集但是也有不属于对方的部分。 \(A \cap B \neq \emptyset\) and $A B A or B $.
2. K-means
核心思想:
每个类都有一个类中心(centroid),数据集里面点到各个类中心的距离最短的那个类就是这个点的类。
杠精提问:咋找这个类中心呀,既然聚类本身就是不知道有什么类的情况下才使用的方法,你还能整出来一个类的中心点?
具体步骤:
- 先要确定一个K,K代表了我们想要有多少类,K=5那最后我们就能分出五类来。
- 随机选择K个初始点,把它们当作就是5个类的类中心。
- 计算每个点到各个类中心的距离,把离它们最近的点加入它们,这样我们就有了有5个充满了数据集的类。
- 计算现在类的中心点(平均值)
- 回到第3步。
- 直到点们都不在类之间移动,中心点不变,或者很少进行移动了就停止迭代,结束。
评估:
像分类一样,聚类也可以用方法评估(不是很准,因为就根本没人知道正确答案)。
我们想象中一个类应该是它们越像,这个类别越准确。因为k-means是用距离来定义这个“像”的,我们也可以用距离来评估。
我们称这个指标为SSE:\(S S E=\hat{\mathbf{a}}^{K} \underset{|c| c}{\hat{\mathbf{a}}} \operatorname{dist}^{2}\left(c_{i}, x\right)\)
别慌,其实就是类里面的所有点到类中心的距离的平方和,这就代表了这个类内部聚不聚拢,把数据集里面所有的类的这个值加起来,就代表了这个分类方法的分类效果。每个类当然是越聚拢越好,所以SSE值也是越低越好。
最优K值:
如何选择K?前面我们说了随便选,但是设想一下,对于一个应该只有2类的问题(生与死),我们给它分五类,那这是不合理不科学的。虽然我们不知道正确答案,但是还是有方法可以判断一下的。
我们尝试很多很多K,从K=2运行到K=10?20?一遍,分别计算各自K的SSE,会有一张如下类似的图
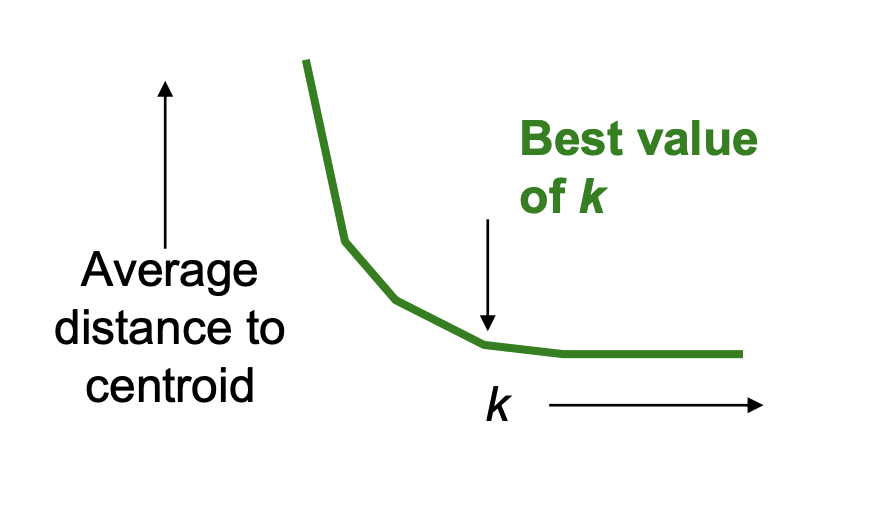
最佳的K值就是图中这样的拐点(经过它之后SSE的变化不明显了)
初始点选择:
初始点的选择是会影响K-means的结果的!所以我们决定用2种方法优化一下初始点错误。
- Multiple runs. 多跑几次,多随机选择几次。
- 每次run一开始选超过K个的初始点,然后选择这些里面距离最远的(most widely separated)
后期处理:
- 可以删掉很小的cluster(可能代表了异常值)
- 分散宽松的cluster(内部SSE很大的类)
- 合并接近的cluster(内部SSE很小的类)
K-means难以解决的问题:
- 每个类拥有不同的大小
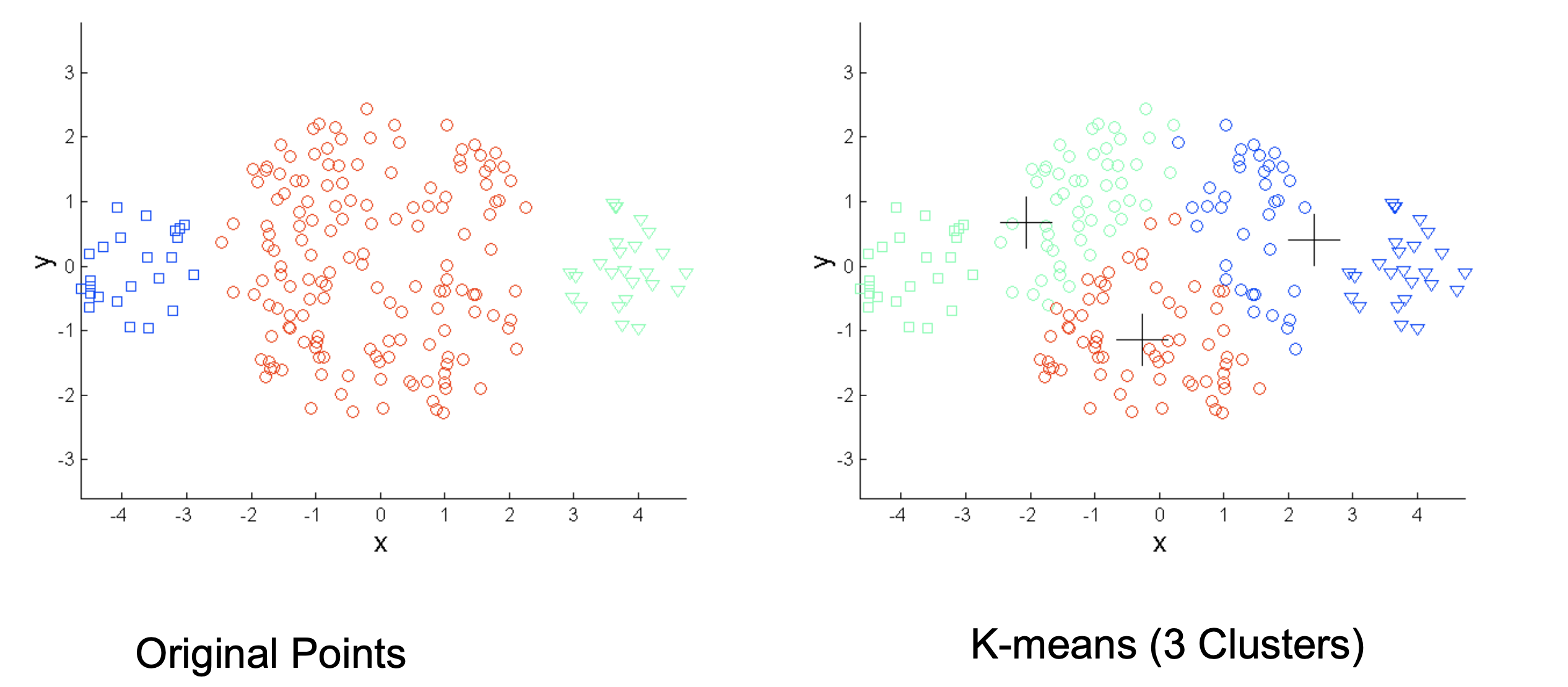
K-means算法只要求点到类中心点距离最短,但会忽略类本身的大小不同。
- 每个类的密度不一样
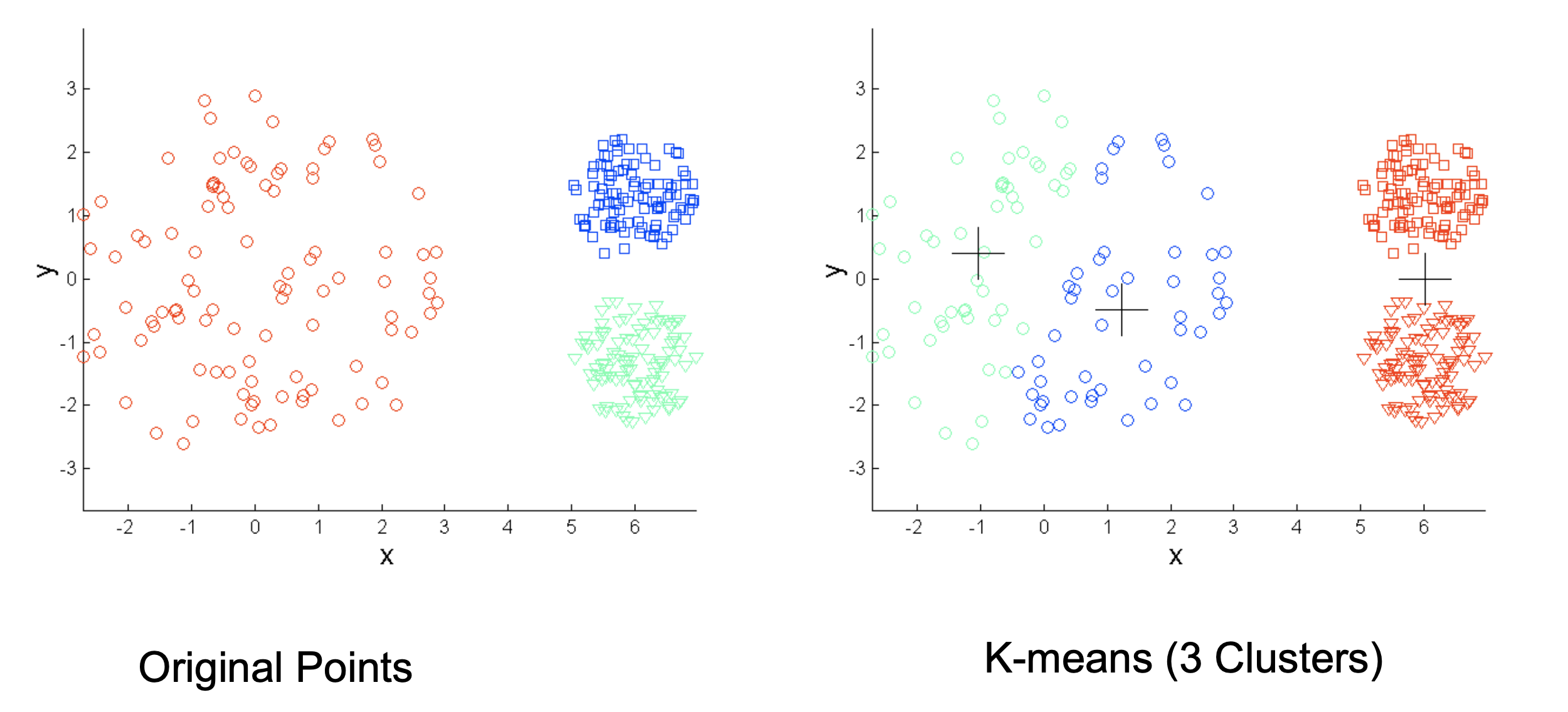
- 每个类的形状不一样
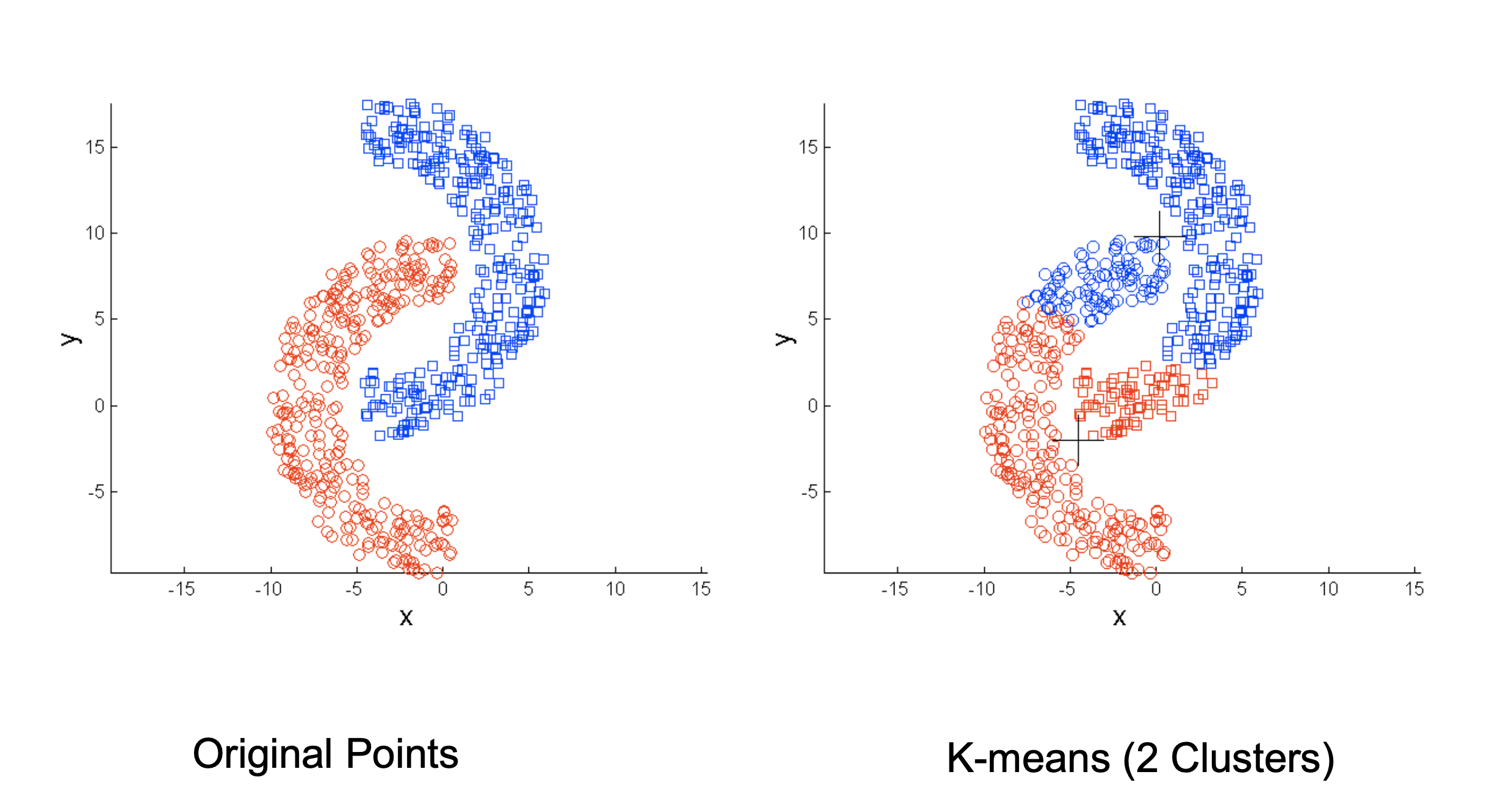
3. Hierarchical Clustering(分层聚类)
概念
我们发现现实生活中有很多的分类都会包含下面更加细分的类,所以就研究出了分层聚类。
我们有2种分层聚类的方法,一种是自下而上(agglomerative)的,一种是自上而下的(divisive)。
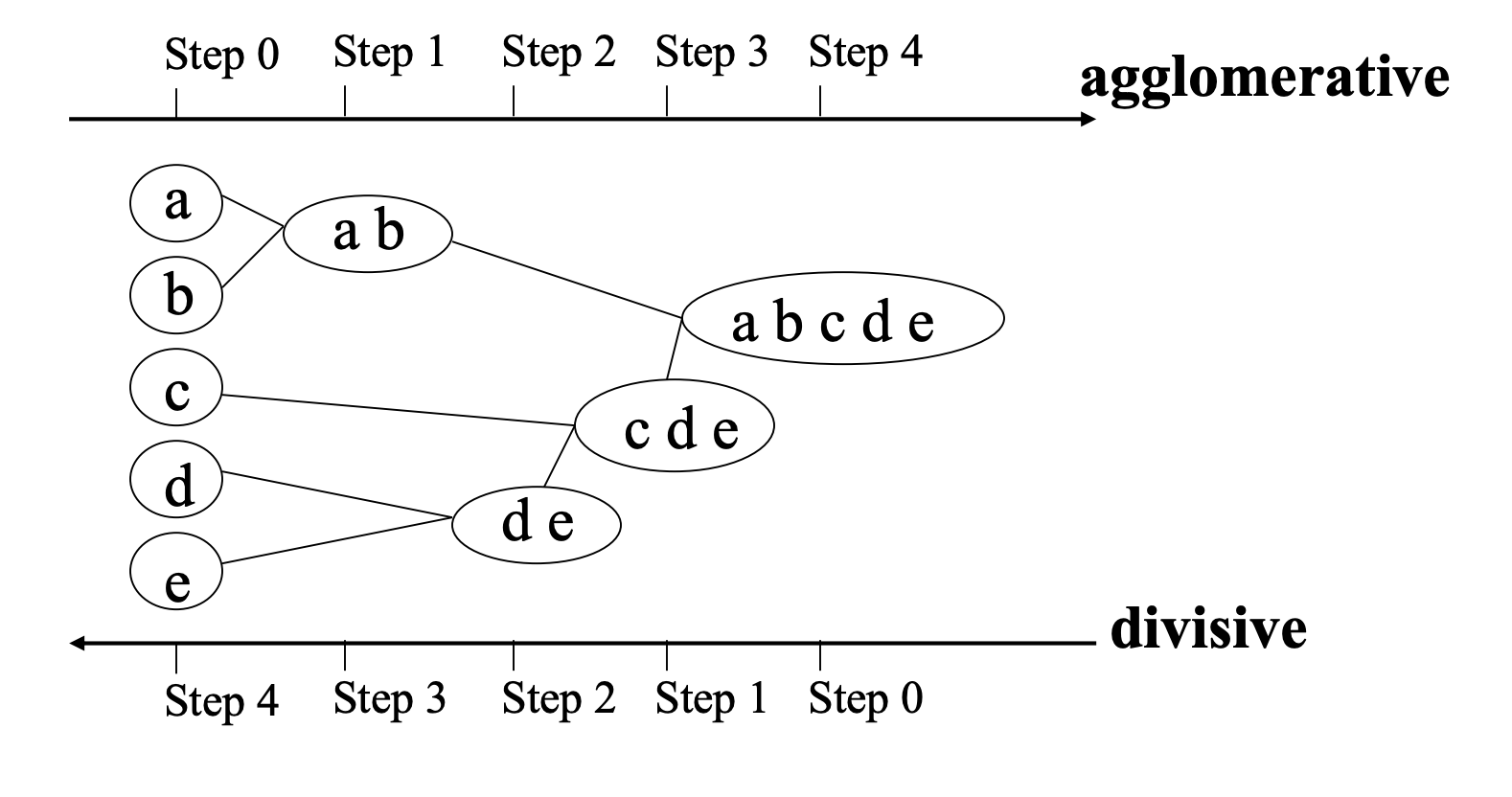
这张图表明了这2种方法的具体步骤。
agglomerative 方法
思路:
- agglomarative是自下而上的,我们得从每一个数据点开始,合并最接近的2个数据点。
- 将合并成功的数据点变成一个类
- 计算这个类与其他的类的距离
- 重复1,2,3,直到最后只剩下一个类(即全体都被包含了)
杠精笑齐:步骤1里面什么叫最接近?步骤3里面的距离怎么算?
例子:
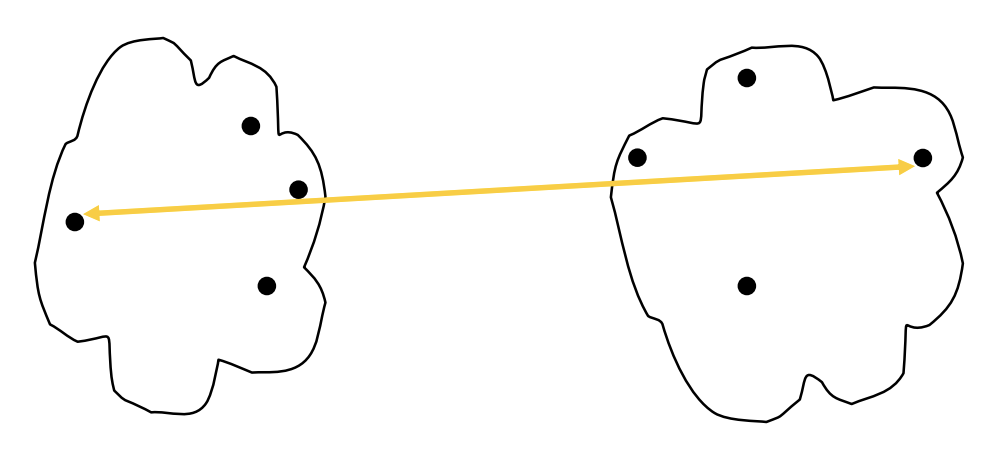
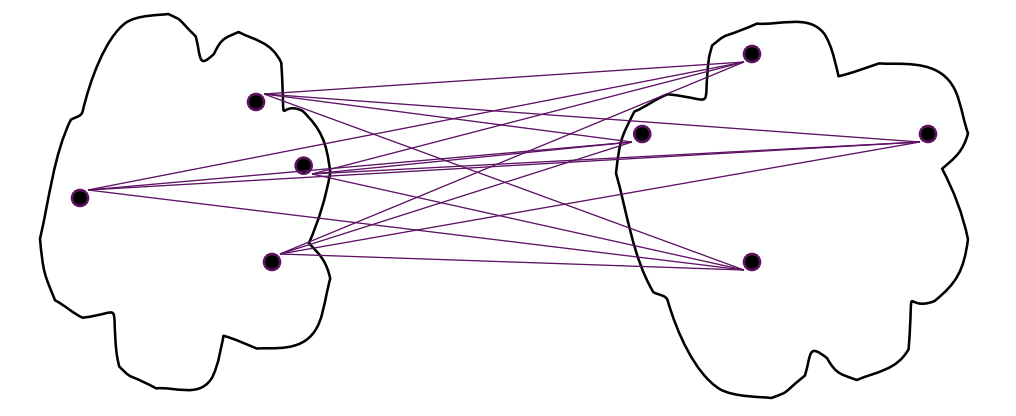
我们有左图中这样的数据分布:
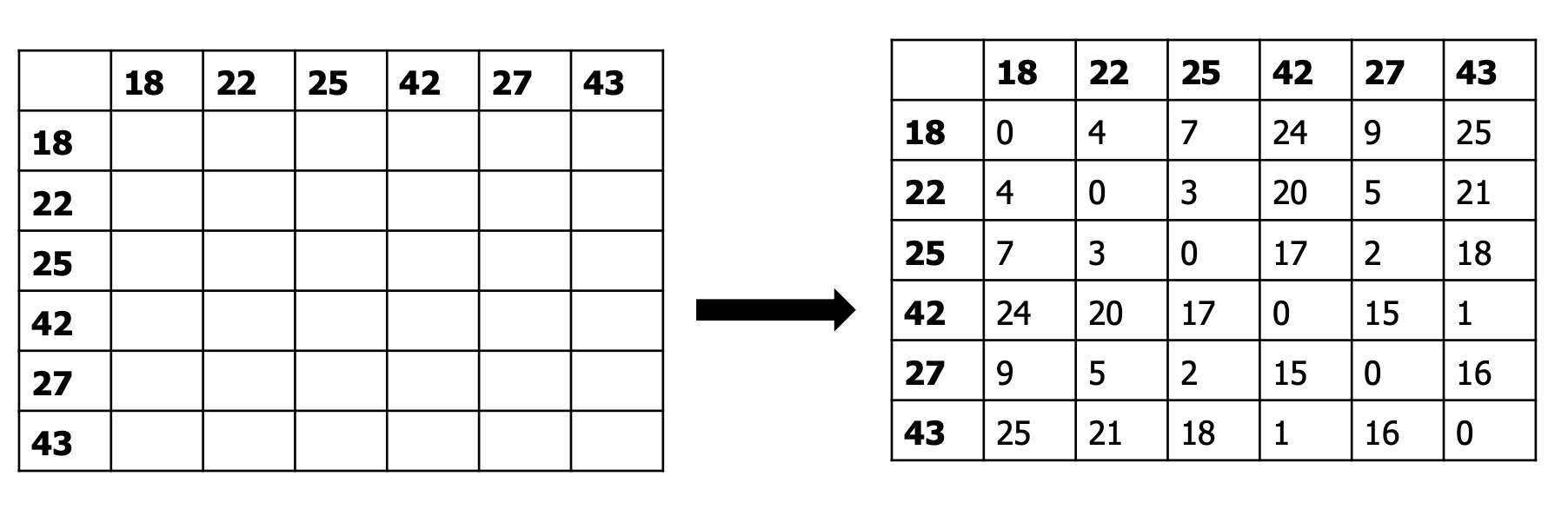
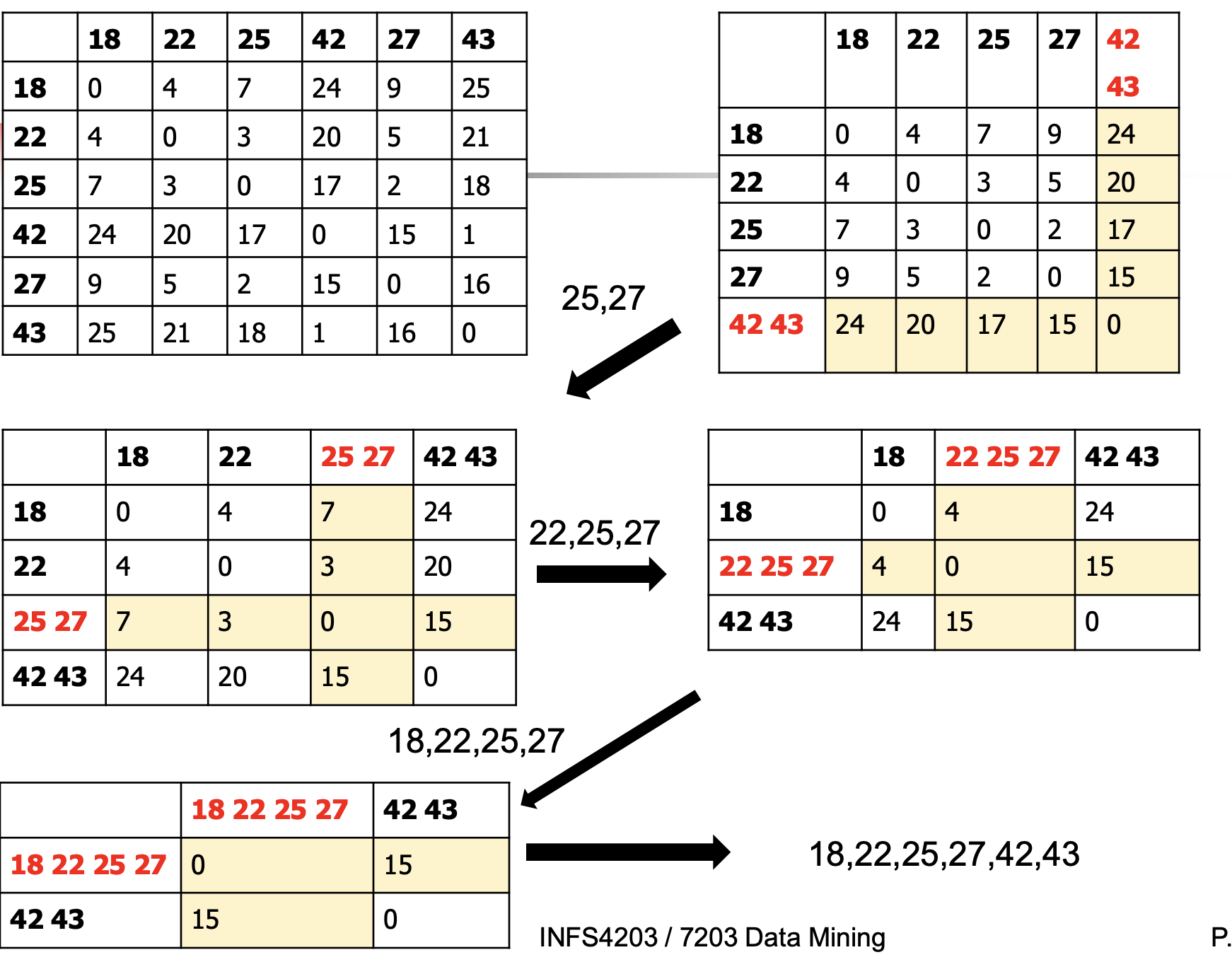
我们先计算每个点之间的距离(这里我们采用[曼哈顿距离](#1. 曼哈顿距离(aka "City block", taxicab, \(L_1\)norm , Manhattan distance)),结果为右上图
合并距离最近的两个点,图中我们得到\(d(42,43) = 1\) 是最近的2个点,合并它们
我们得到了一个新的距离矩阵:
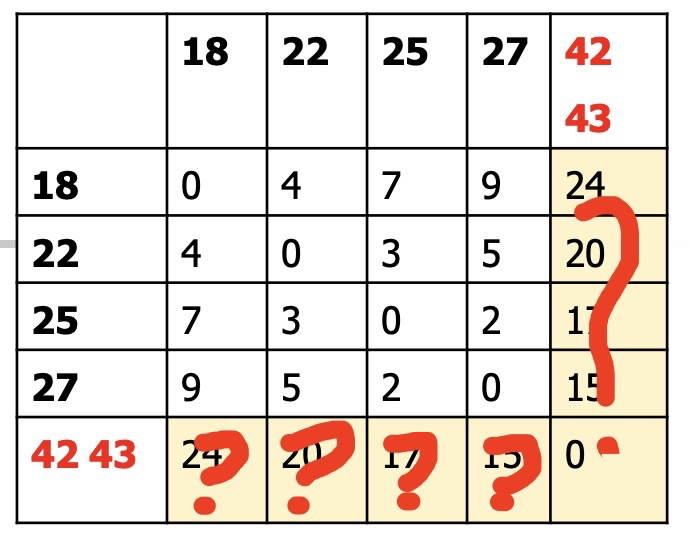
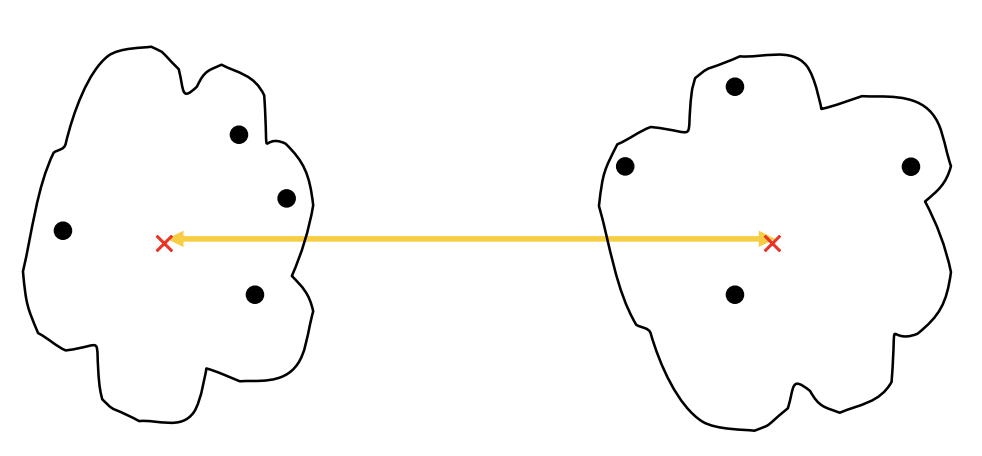
有了一个新的问题,我们知道42,43分别对其他点的距离,但是我们怎么计算(42,43)这个新的类到其他点的距离呢? 也就是图中的黄色部分是怎么计算的呢?
当我们知道计算这个距离后,我们只需要继续重复合并最近的2个点(类),直到只有一类结束。
我们有很多种计算合并后的新类与其他类的距离计算方式。
MIN:
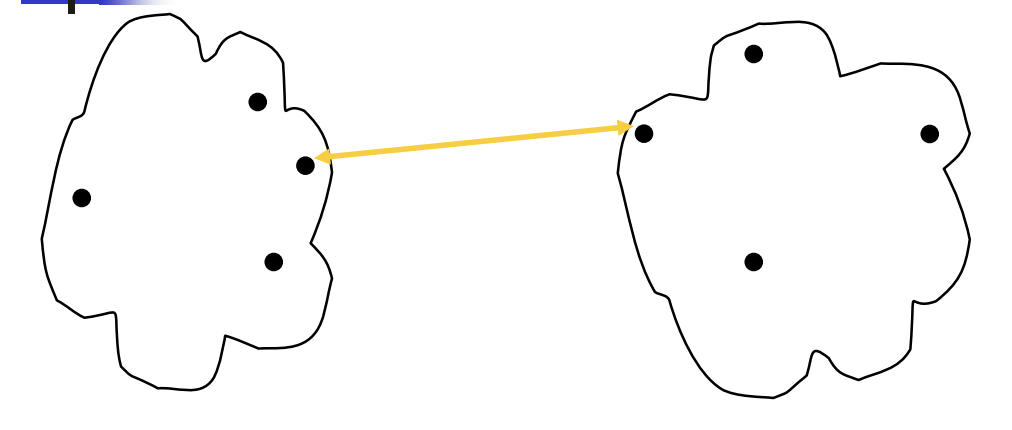
我们选取新类所有点到其他类中所有点中最短的距离,作为距离
例如在我们的例子中我们就用了MIN方法:
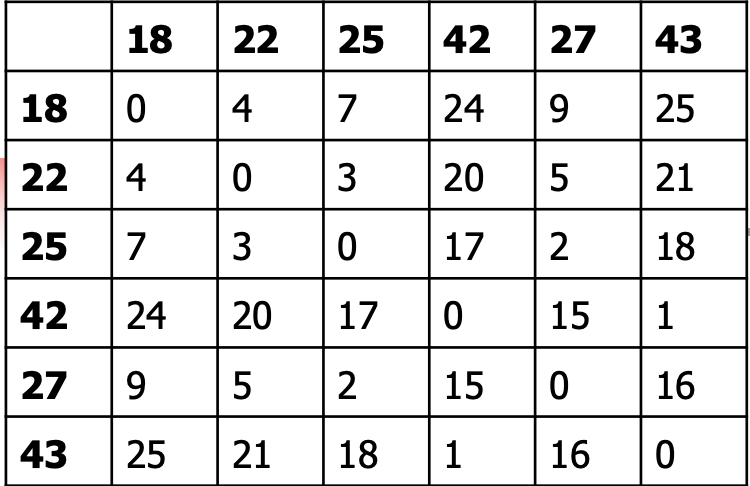
我们计算(42,43)新类对类(18)的距离:
我们计算d(42,18) = 24, d(43,18) = 25, 我们使用MIN为距离即(42,43)类对(18)的距离为24.
以此类推得到(42,43)对所有其他类的距离。
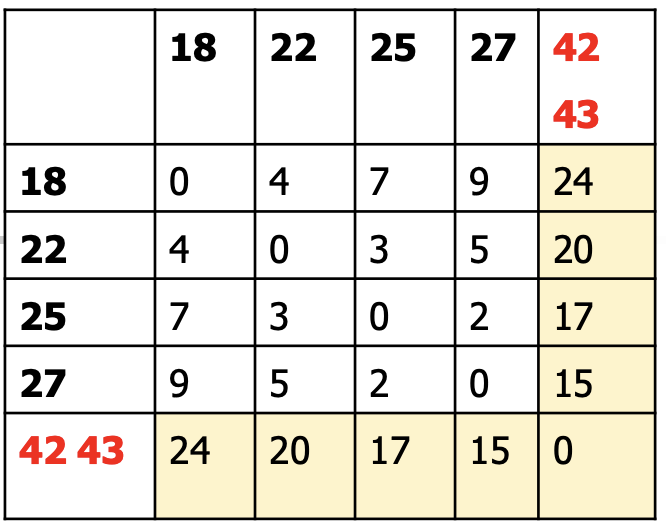
接下来重复步骤1,步骤2,找到距离最小的两个类为d(25,27) = 2,合并它们在计算(25,27)对其他类的距离。一直重复到只有一个类。具体步骤为:
我们得到最后的dendogram为:
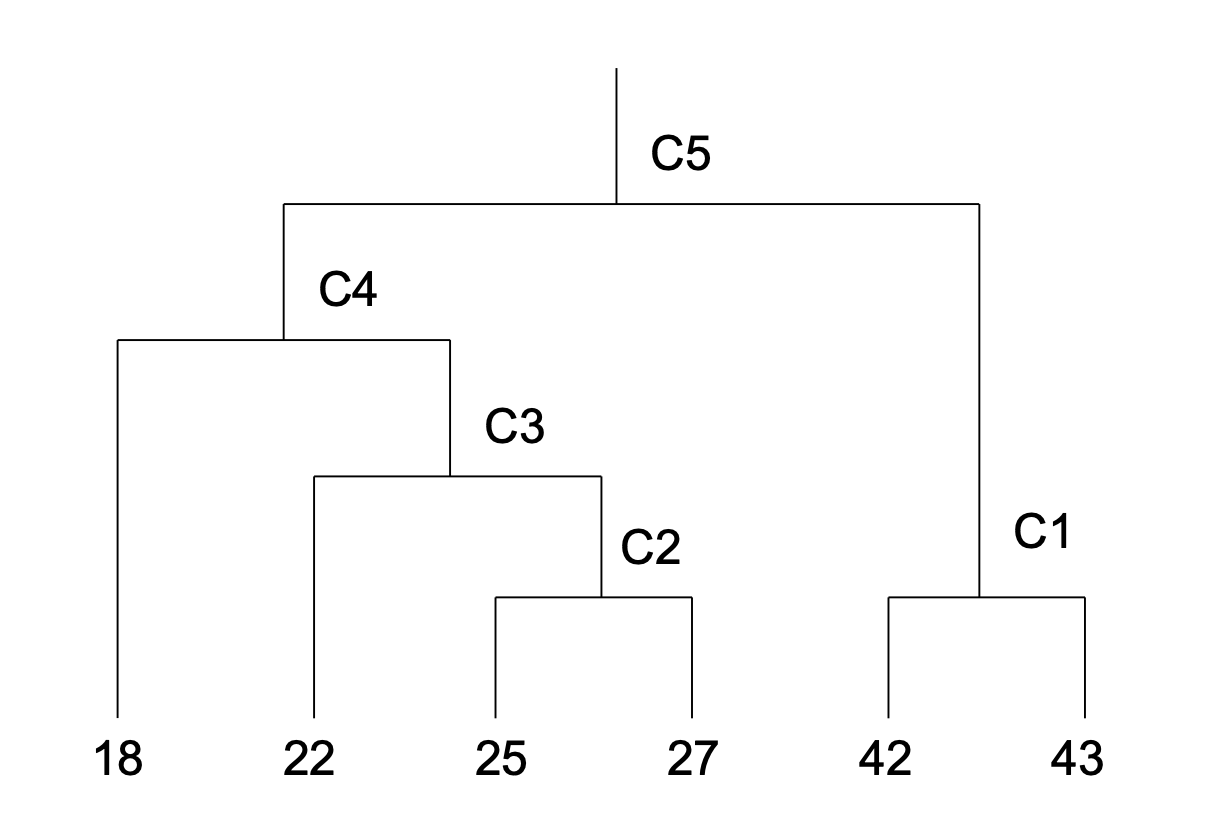
你想要分几类就在这个树图里切一刀,例如你想要有2个类,就把\(C_5\)切了,就把数据分为了\((C_4,C_1)\)两类。
后面的各种方法都类似MIN
MAX:
把用最小的距离变成用最长的距离:
Group Average:
距离变成计算所有点到点的距离的平均值:
Centroid:
计算每个类的类中心,距离为2个类中心的距离:
Limitation of MIN:
对noise很敏感:
只用一个值
产生链接现象(chaining phenomenon):
两个本来很远,一定不属于同一类的点p,q,但是它们之间有很多点,这样p每次最近的点都是p,q连线之间的点,最后会导致p和q分到了同一类。
Limitation of MAX:

很难对大小不同的类进行分类。
但是MAX方法抗噪声和异常值的效果很好,所以一般编程软件关于分层聚类的参数默认都用MAX方法。
divisive 方法
构建最小扫描树(Minimum Spanning Tree)
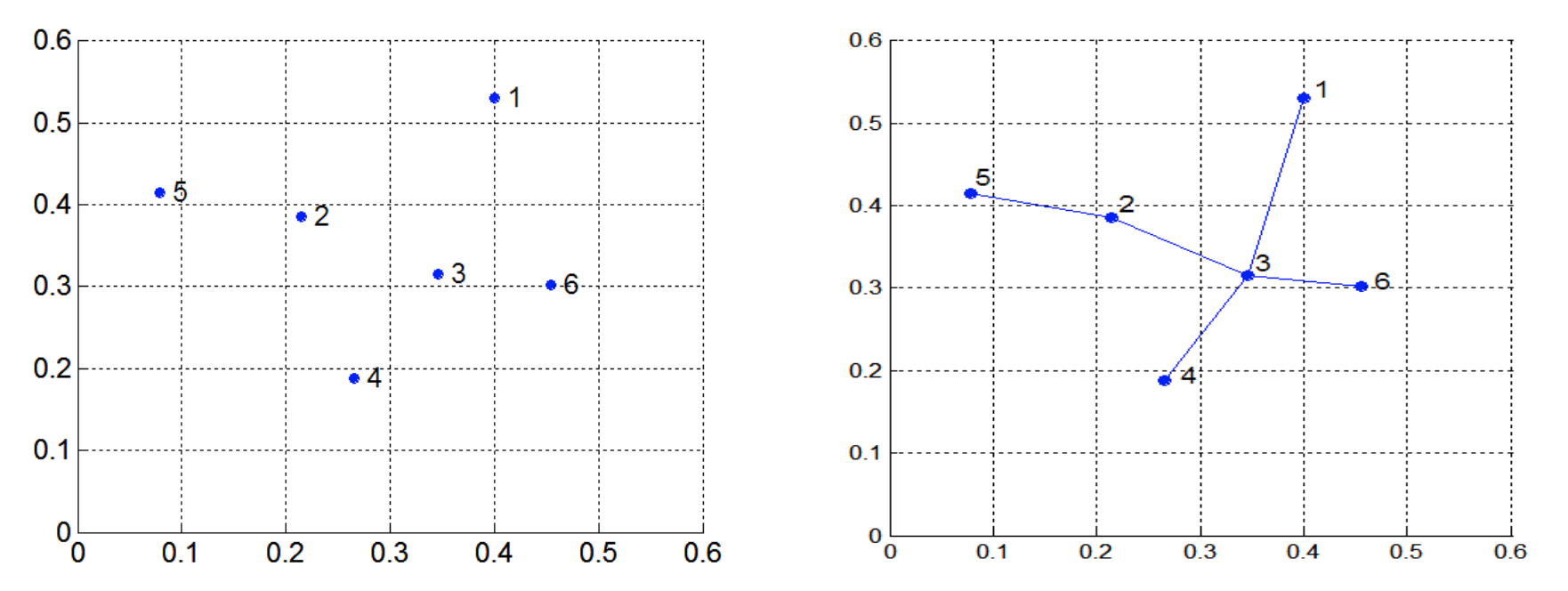
如图,首先找距离最近的两个点连线,接下来找最近的(p,q)连线,其中p是在已经连线的点中,q是没有被连线的点。找到q后将q和p连线。重复过程。
当你完成了Minimum Spanning Tree后,你减掉最后几次连成的线,就是完成分类(根据你要有多少个类)
4. Density-based clustering
基于密度的聚类经常用在我们的数据在局部区域有很高的密度时
例如:

DBSCAN
DBSCAN就是针对以上情况的算法。
首先我们有2个自己定义的值:
EPS: 以点为圆心,以EPS为半径做圆,圆内其他数据点的个数我们就称为密度。
MinPts:当圆内的点个数(密度)超过了MinPts时(包含点本身),我们称这个点是core point
如果这个点密度没有超过MinPts,但是它在core point附近,称为Border point
或者说Border point的EPS里会有core point点出现。
如果这个点既不是core point也不是border point,就称为noise point
例子:
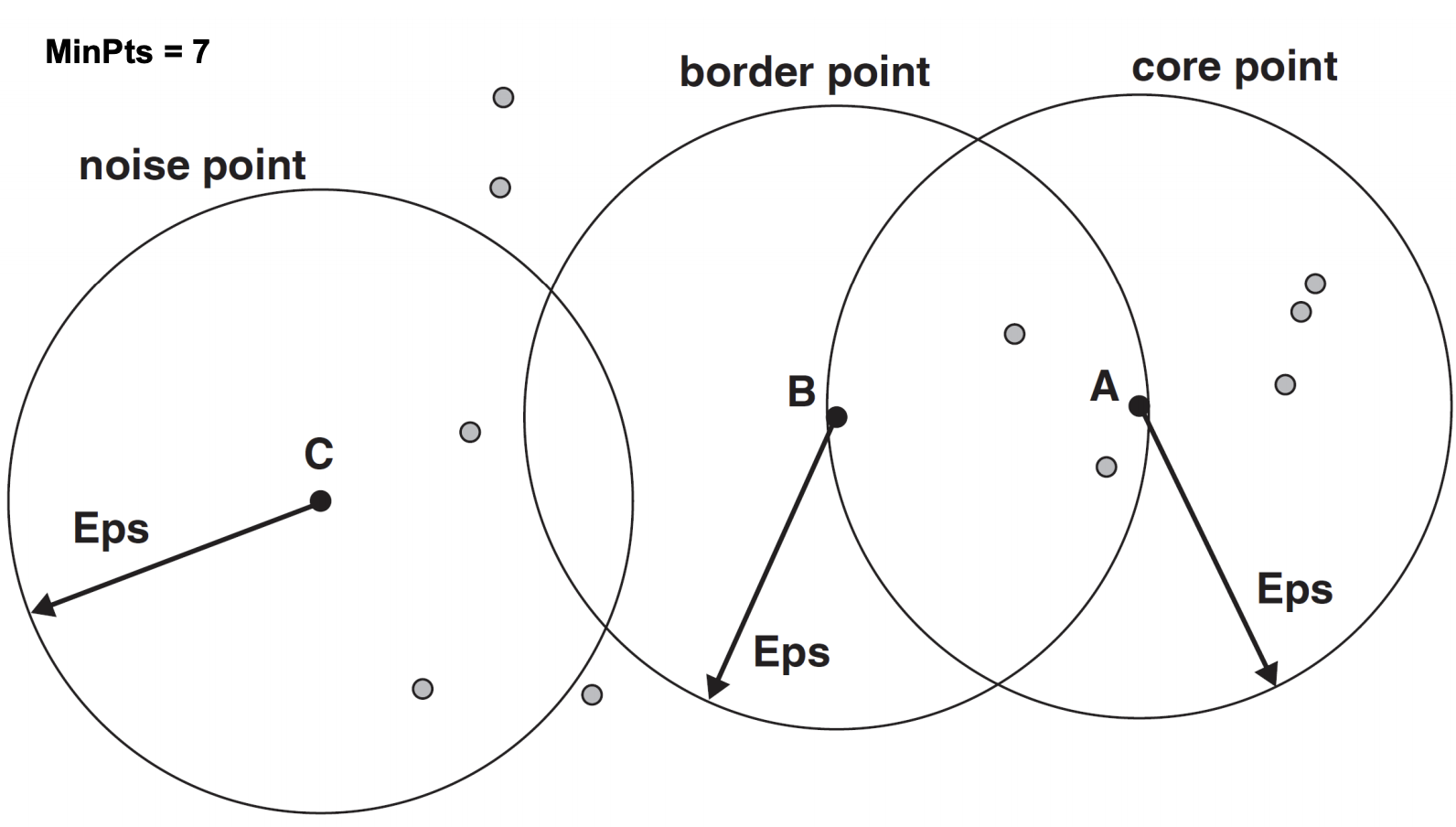
具体聚类步骤:
- 将所有点贴上core,border,noise point的标签
- 删除noise point
- 将在EPS范围内的所有core points连上线
- 每一个完成连线的core points组即作为一类
- 将每个border point分配给任意它临近的core point的那一类
例子:
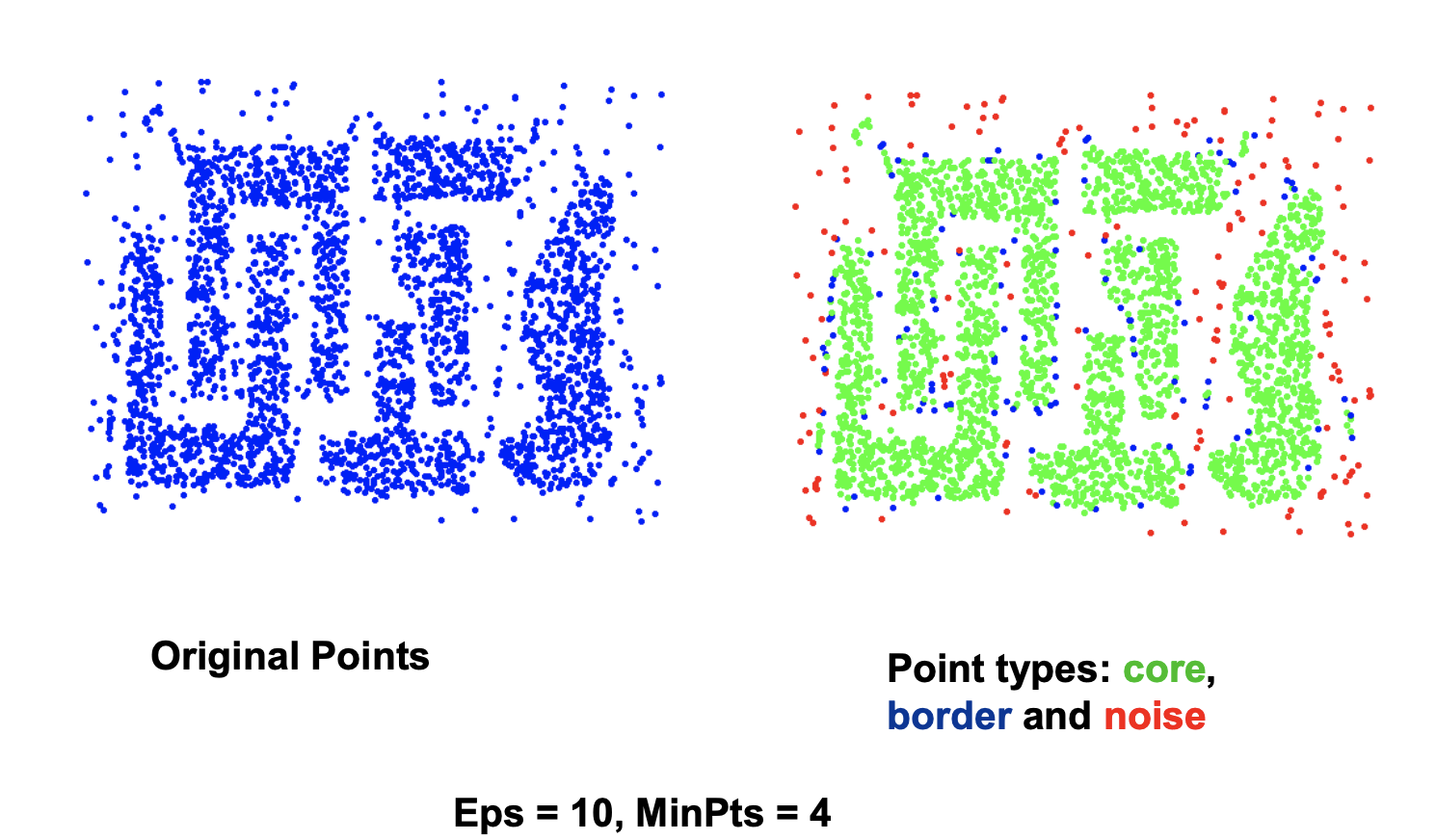
DBSCAN的缺点
DBSCAN处理不了具有不同的密度的类(一个类里面有多种密度)。它只能区分高密度的类和低密度的类,但是处理不了密度都相同,但其实是不同的类的情况。需要有一点的背景知识才能使用。
如何选取EPS和MinPts
- 选取一个k,计算k-distance,即点到离它最近的第K个点的距离
- 对这些k-distance进行升序排序
- plot画图如下
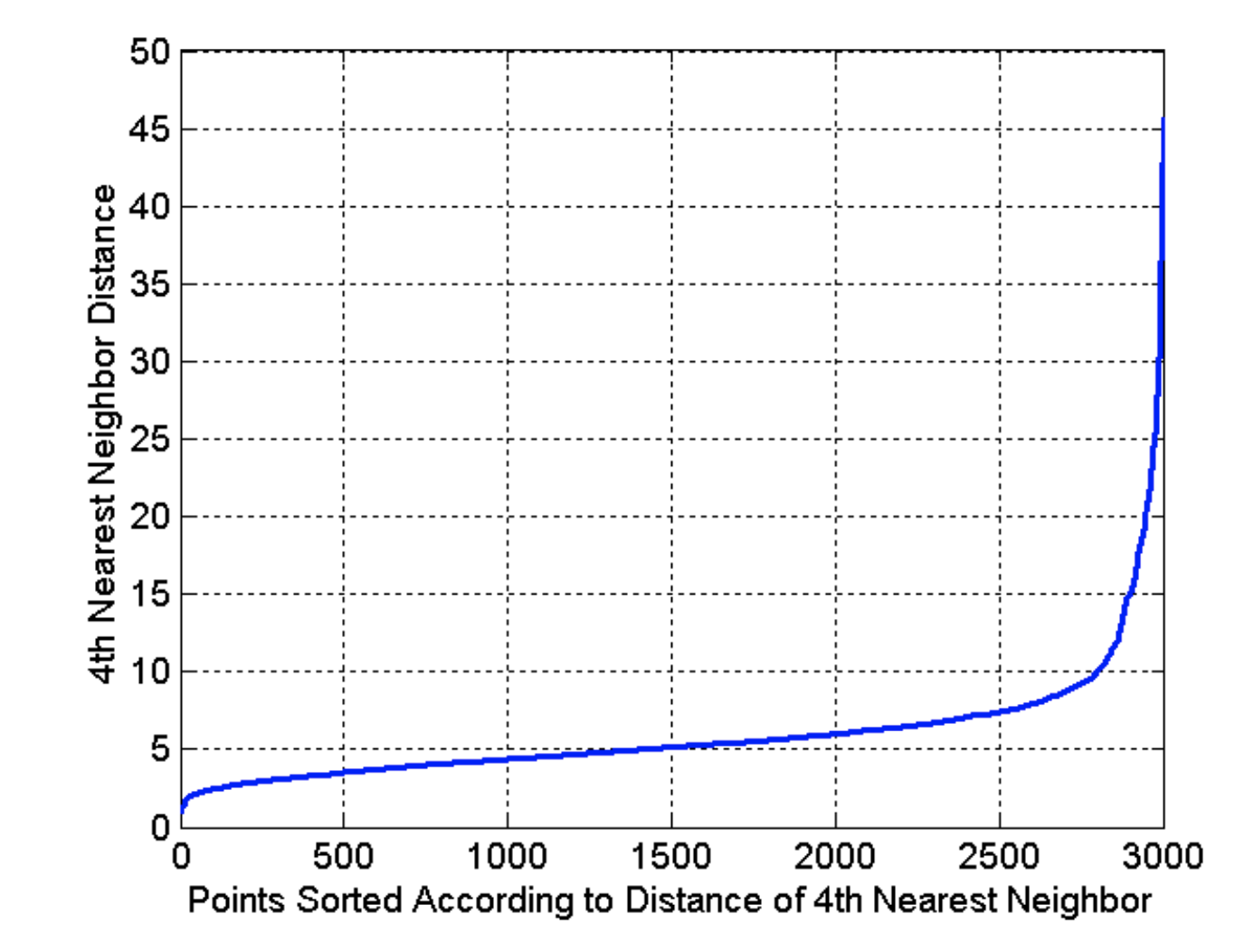
纵坐标为排序的k-distance,横坐标为点的数量。
我们在图中可以找到一个sharp change(图中k-distance = 10)的时候,
我们就选这个k-distance(10)为EPS,k(4)为MinPts。
一般根据经验,k都选4
5. Cluster Validity
对于classification,我们有accuracy,recall,precision等评估方式。
那对于Cluster我们能有什么呢?
首先我们知道这是很困难的,因为我们并没有正确答案,我们自己都不知道数据集的标签。当一种分类算法给数据上标签后,自然而然我们也不知道它是对的还是错的。
但是我们还是要寻找一些可能的方法的,用这些方法可以帮我们来判断:
- 这么多聚类方法,哪个比较好,该用哪个?
- 类和类之间的信息
- 类内部的信息
- 避免噪声异常值之类的干扰
根据不同的聚类算法,我们可以得出完全不同的分类。例如:
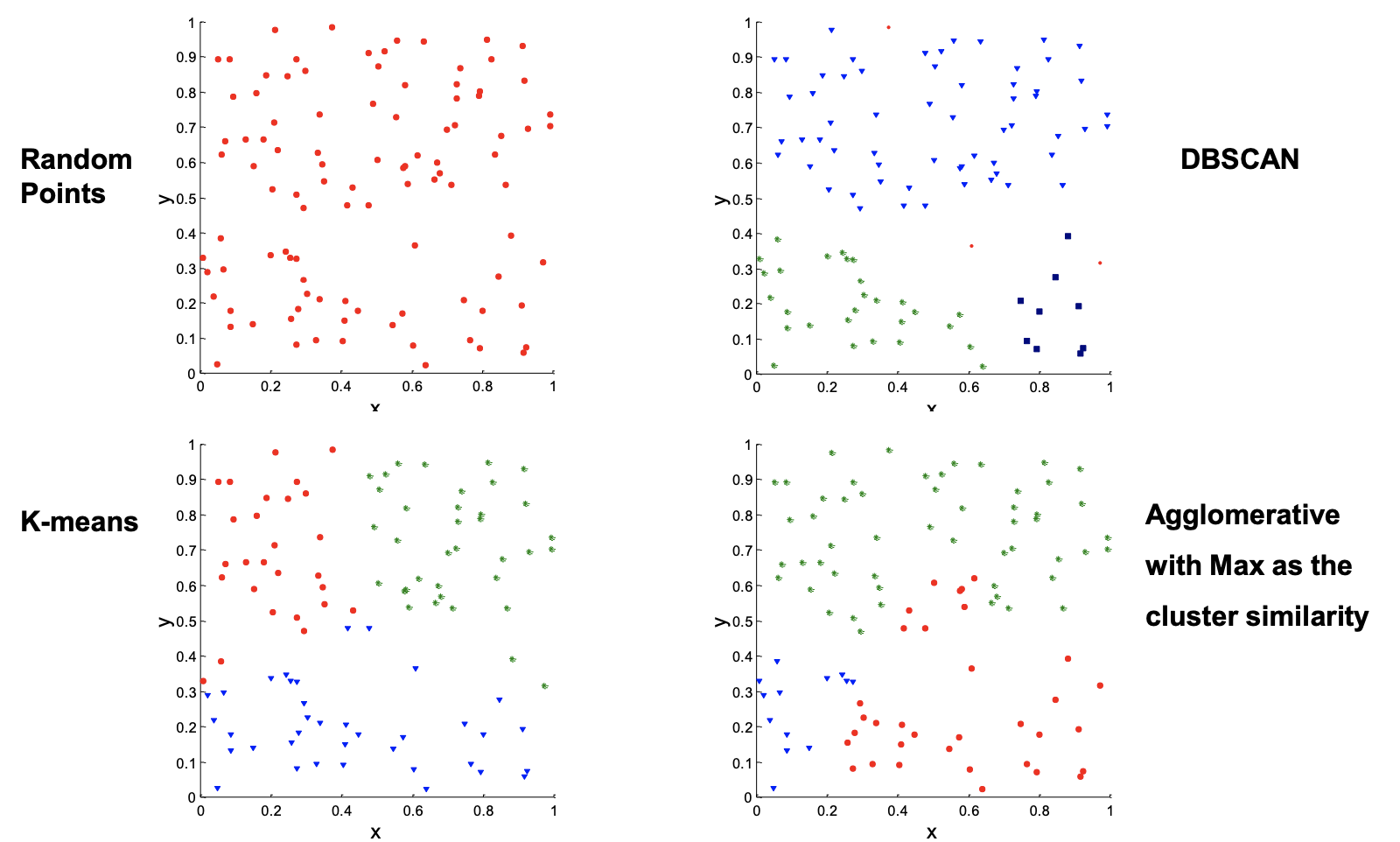
下面介绍几种不同的方式:
1. Groud Truth
Groud Truth是这个数据集真实的标签。
非常的扯淡,因为我们都知道真实的标签还干嘛要用聚类方法。
不过这个方法可以帮助我们验证我们聚类算法,当发现了一种新的聚类算法的时候,可以在已知数据集上进行,并用Groud Truth来判断。
方法也特别的简单。
groud truth: 真实的标签/类为$ P = {P_1,…,P_s}$
聚类方法得出的标签/类为 \(C = \{C_1,…,C_t\}\)


例子:
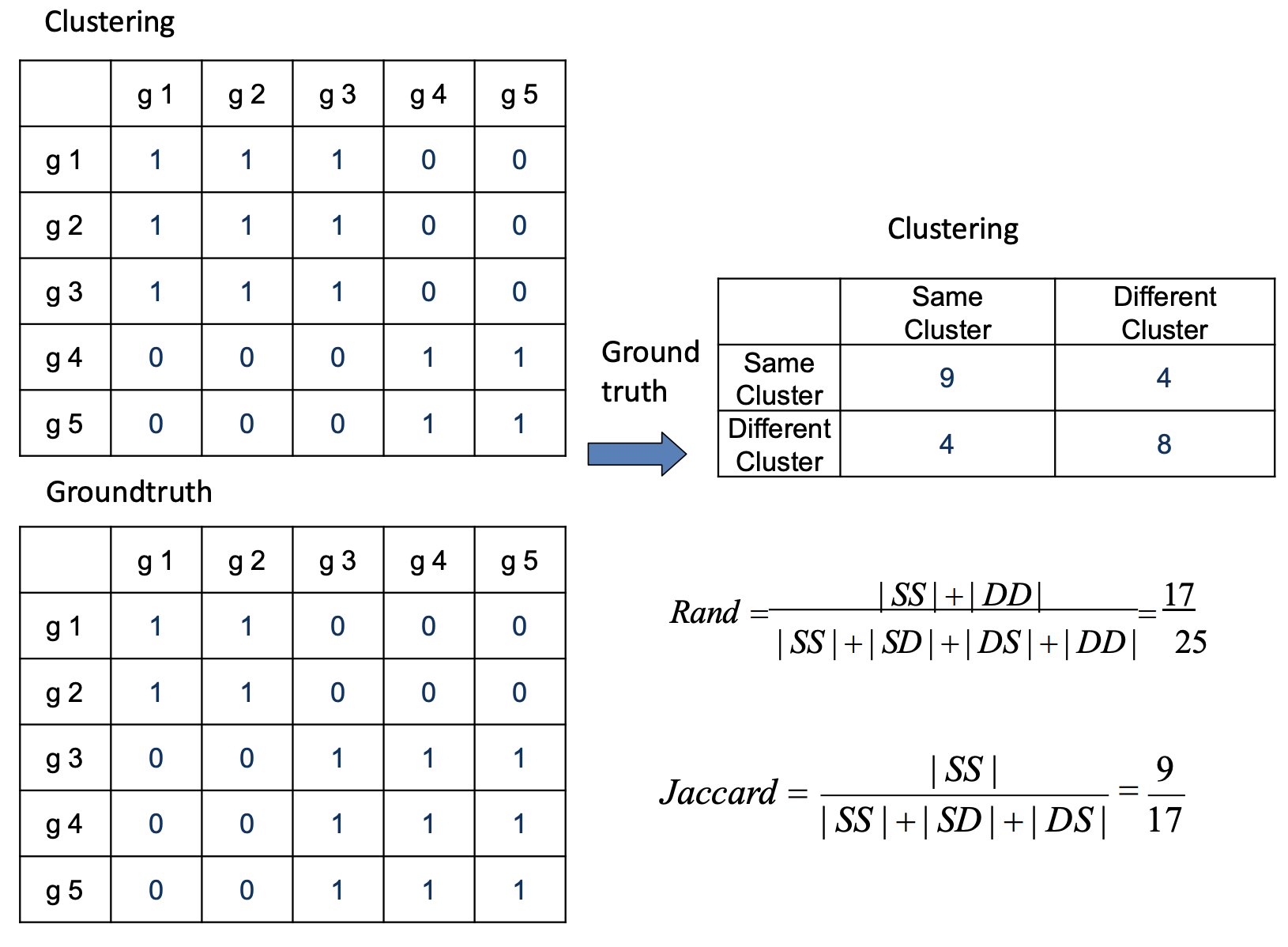
- Purity
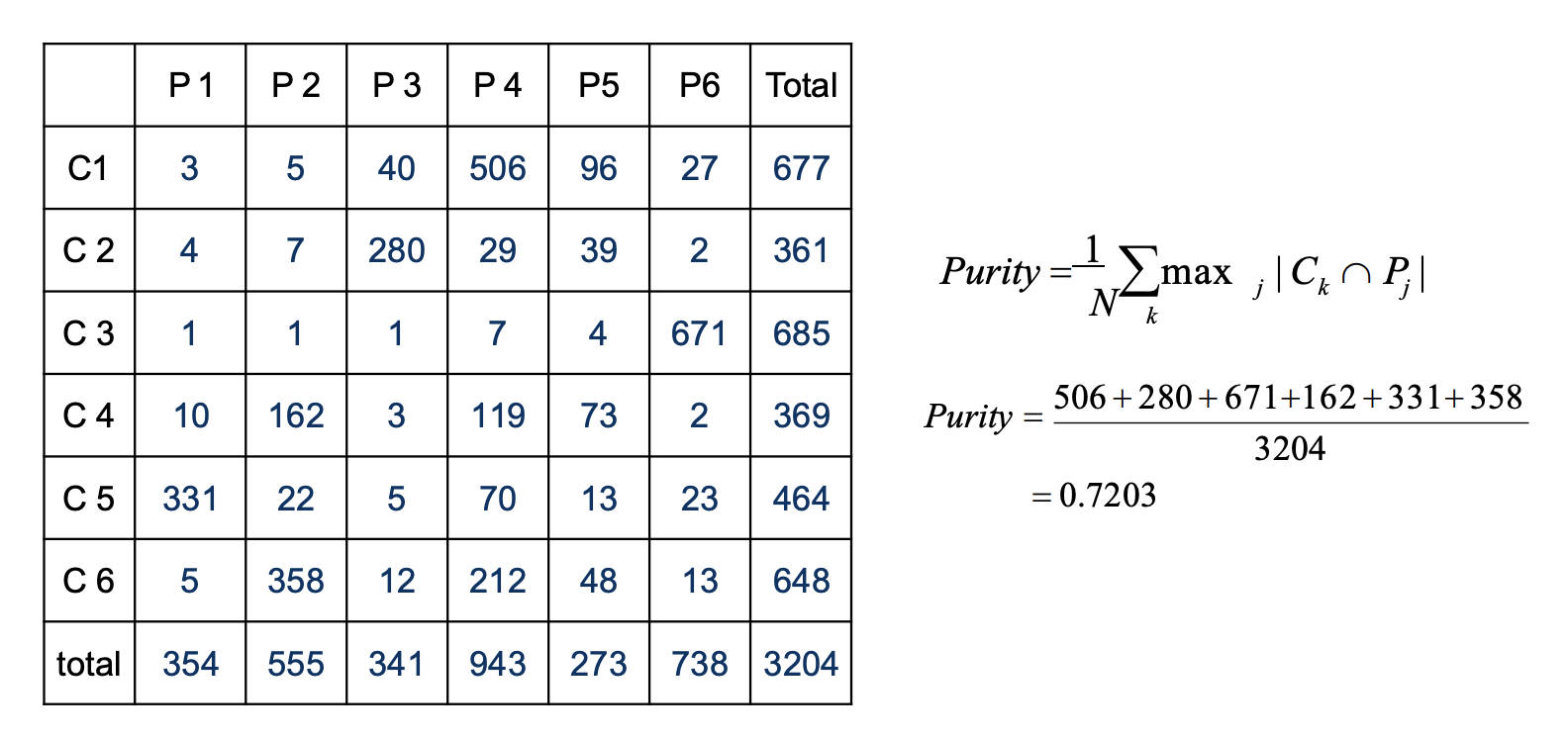
2. Internal Measure
只使用数据集自身的信息来判断。
- Cohesion:类的聚拢程度
- Separation:类和类之间的离散程度
SSE和BSS
计算cohesion的方法类似于之前提到的SSE:
\(S S E=W S S=\sum_{i} \sum_{x \in C_{i}}\left(x-m_{i}\right)^{2}\)
计算separation用WSS:
\(\begin{aligned} B S S &=\sum_{i}\left|C_{i}\right|\left(m-m_{i}\right)^{2} \\-& \text { Where }|C| \text { is the size of cluster } i \end{aligned}\)
例子:

Silhouette Coefficient:
这种方法既考虑了cohesion也考虑了separation
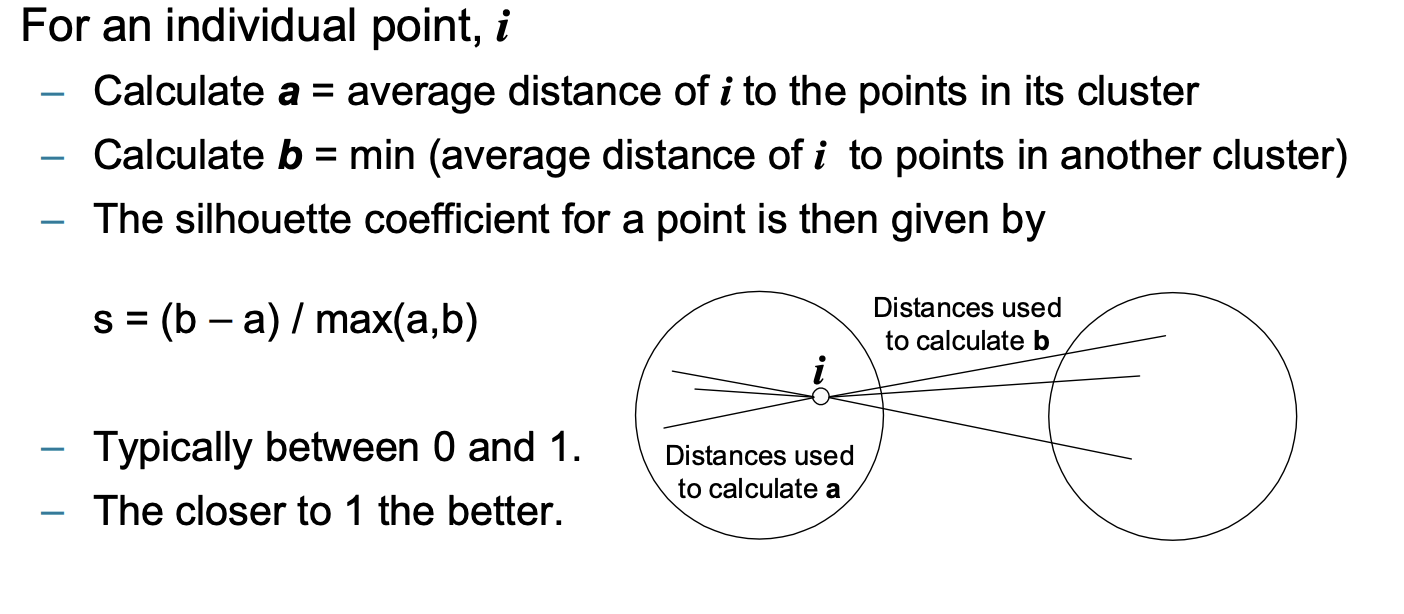
a是i点到它类内其他点的平均距离(cohesion)
b是离i最近的类的所有点的平均距离(separation)
Correlation with Distance Matrix
计算2个矩阵:
- distance matrix(每个数据的距离)
- incidence matrix(每个数据是否属于同一类)
计算公式为:
\(r=\frac{\sum_{i=1, j=1}^{n}\left(d_{i j}-\bar{d}\right)\left(c_{i j}-\bar{c}\right)}{\sqrt{\sum_{i=1, j=1}^{n}\left(d_{i j}-\bar{d}\right)^{2}} \sqrt{\sum_{i=1, j=1}^{n}\left(c_{i j}-\bar{c}\right)^{2}}}\)
d是distance matrix,c是incidence matrix
|r| 越高代表聚类效果越好。 (只考虑绝对值)
下图是用k-means对2个数据集做聚类后,求出的correlation值
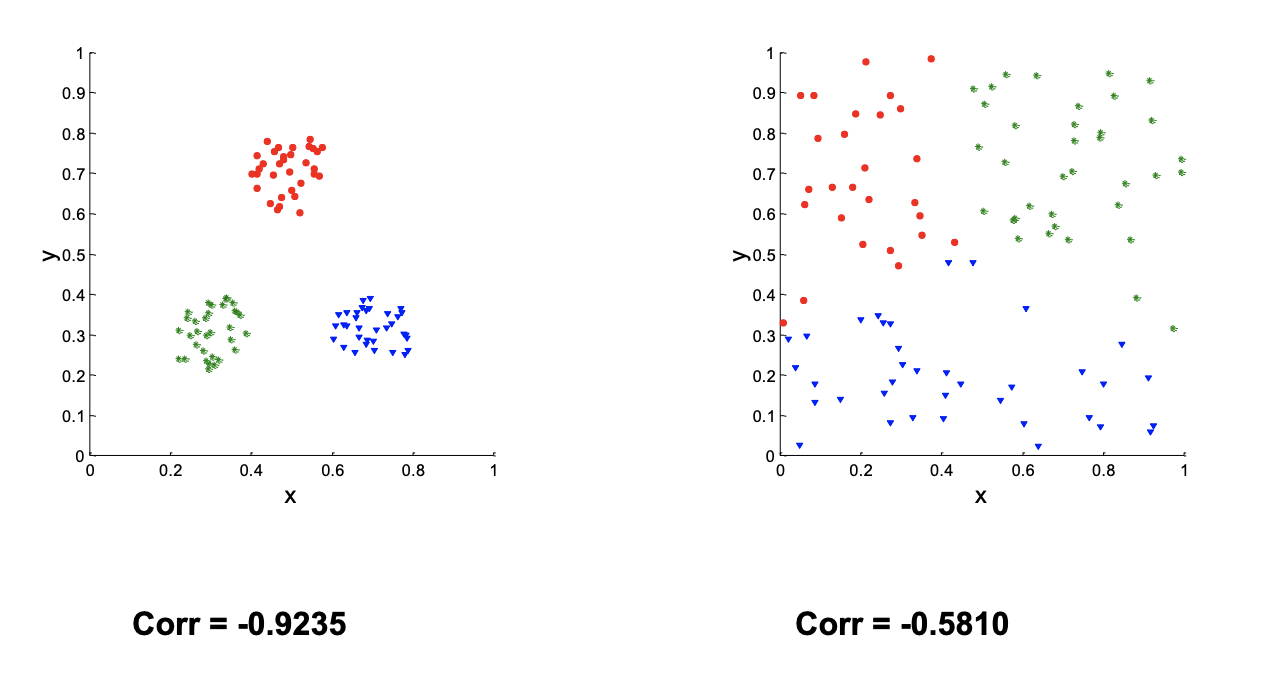
|Corr|越大,效果越好。
3. Statistical Framework for SSE
当我们想要评估一个聚类方法的时候,我们可以把这个方法用在目标数据集和很多个随机生成的数据集中。
分别计算它们的SSE。
当我们发现,目标数据集的SSE和随机数据集的SSE非常的不同时,我们就能知道这个聚类方式对目标数据集是有效的(即它只对目标数据集效果好,而不是随便什么数据集都是效果好的)。
IV. Association Rule 关联性分析
目的:发现事物之间有趣的规则。
要是我们学会了这个,可以做广告推荐。
例如你逛超市的时候看一个东西,比如牛奶,如果我们知道购买牛奶的人有很高概率买面包,那超市在牛奶旁边就在面包,消费者很有可能直接顺手拿了。
而如何计算这个概率,了解对象之间的关联性分析,就是此章的内容。
定义notation:
一个association rule可以表示为 $ X Y$
前面的例子可以显示为 \(牛奶 \rightarrow 面包\)
1. Measures
1. Support
Rule: $ X Y$
有2种support的算法,第一种是计算基数(频数)
\(Support( X \rightarrow Y) = | X \cup Y|\)
第二种是计算概率
\(Support( X \rightarrow Y) = P(X \cup Y)\)
例子:
我们有一个集合为{milk, coke, pepsi, beer, juice}
我们的阈值设定为当support > 3 时,判断这个rule是frequent
\(B_1 = \{m, c, b\}, B_2 = \{m, p, j\}, B_3 = \{m, b\}, B_4 = \{c, j\}, B_5 = \{m, p, b\}, B_6 = \{m, c, b, j\}, B_7 = \{c, b, j\}, B_8 = \{b, c\}\)
\(S(m \rightarrow b) = 4, S(b \rightarrow c)= 4 , S(c \rightarrow j) =3\)
Support 并不关心顺序,上面的反过来也行。
2. Confidence
\(\text { Confidence }(\mathrm{X} \rightarrow \mathrm{Y})=\mathrm{P}(\mathrm{Y} | \mathrm{X})=\mathrm{P}(\mathrm{X} \cup \mathrm{Y}) / \mathrm{P}(\mathrm{X})\)
根据定义我们知道:
\(\text { Support }(\mathrm{X} \rightarrow \mathrm{Y}) = \text { Support }(\mathrm{Y} \rightarrow \mathrm{X})\)
\(\text { Confidence }(\mathrm{X} \rightarrow \mathrm{Y}) \neq \text { Confidence }(\mathrm{Y} \rightarrow \mathrm{X})\)
找到一个我们认为有关联的关系需要同时超过我们给定的support阈值和confidence阈值。
2. Apriori Algorithm
对于一个超级大的数据集,对每个item和它们的组合分别求出support和confidence来找出关联性信息是基本不可能的(计算量太大)。
首先我们发现对于一个组合\(\{X,Y,Z,…,\}\), 它的support都是相等的而无关\((\rightarrow)\)。但是confidence是不同的。
由此我们发现,计算support非常的快(比confidence快),所以我们可以先找满足support的item,再在这个item里找满足confidence的关系。
超市里面有商品{A,B,C,D,E},则它们所有可以的item组合为如下:
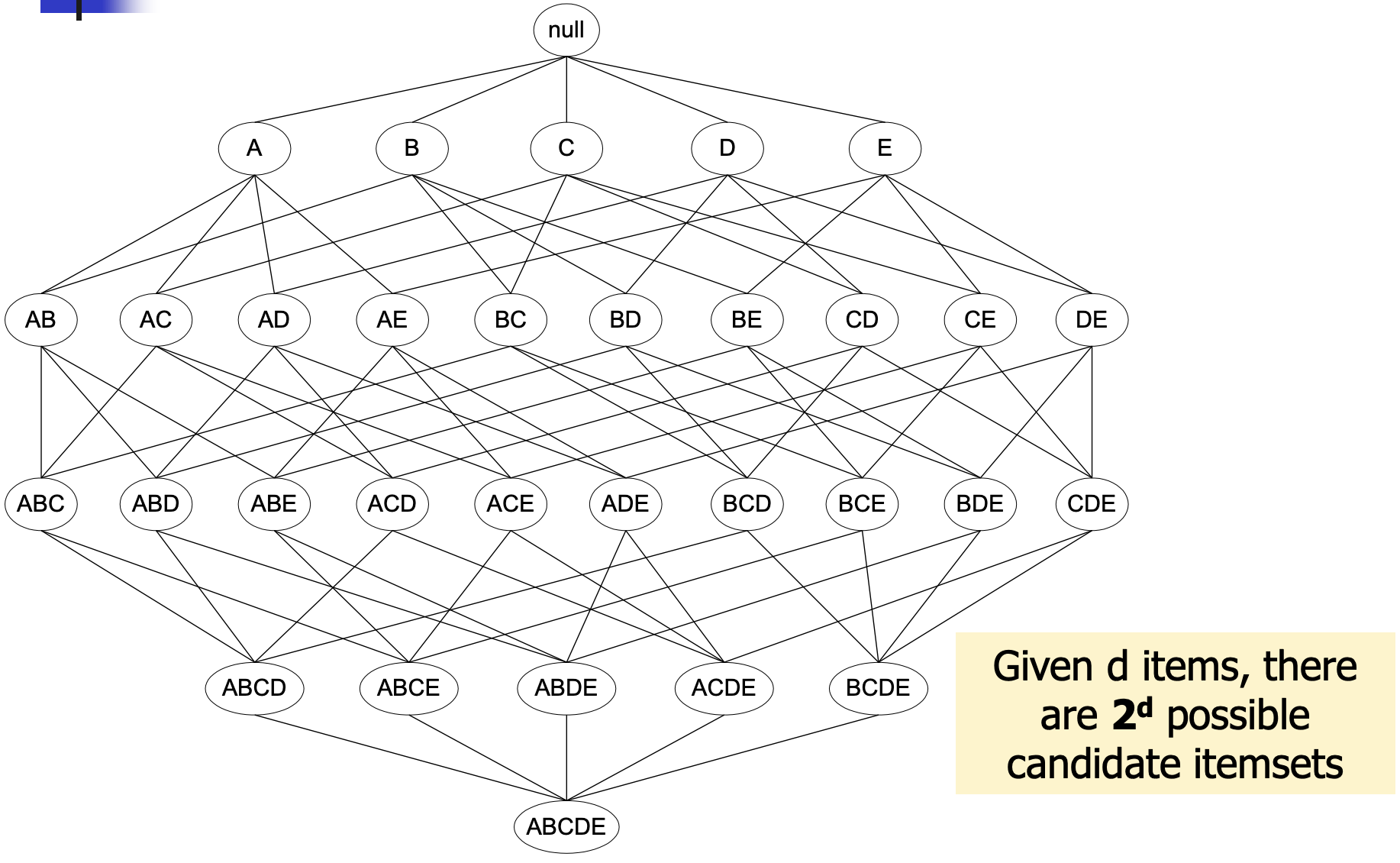
Apriori定理:如果一个item不是frequent的,它的所有子集subitems都不是frequent的。
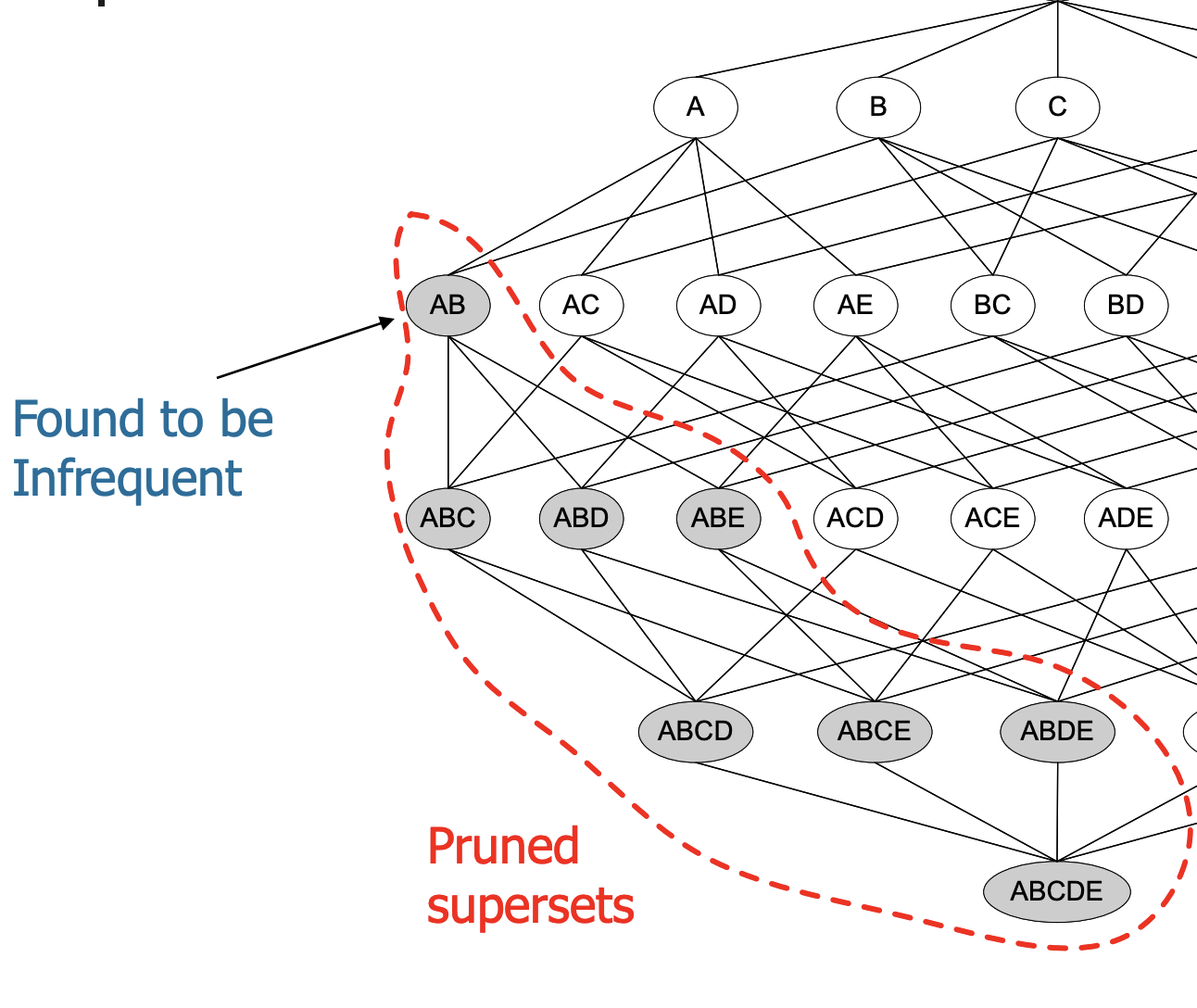
如图当你计算出AB不是frequent后,不用在计算任何包含AB的item了,大大的减少了计算量。
算法过程:
- 计算单个item的support
- 剔除低于阈值support的item,保留满足条件的单个item
- 生成包含2个对象的item,计算support,剔除不满足的,保留满足的
- 继续生产,计算,删除,保留
例子:
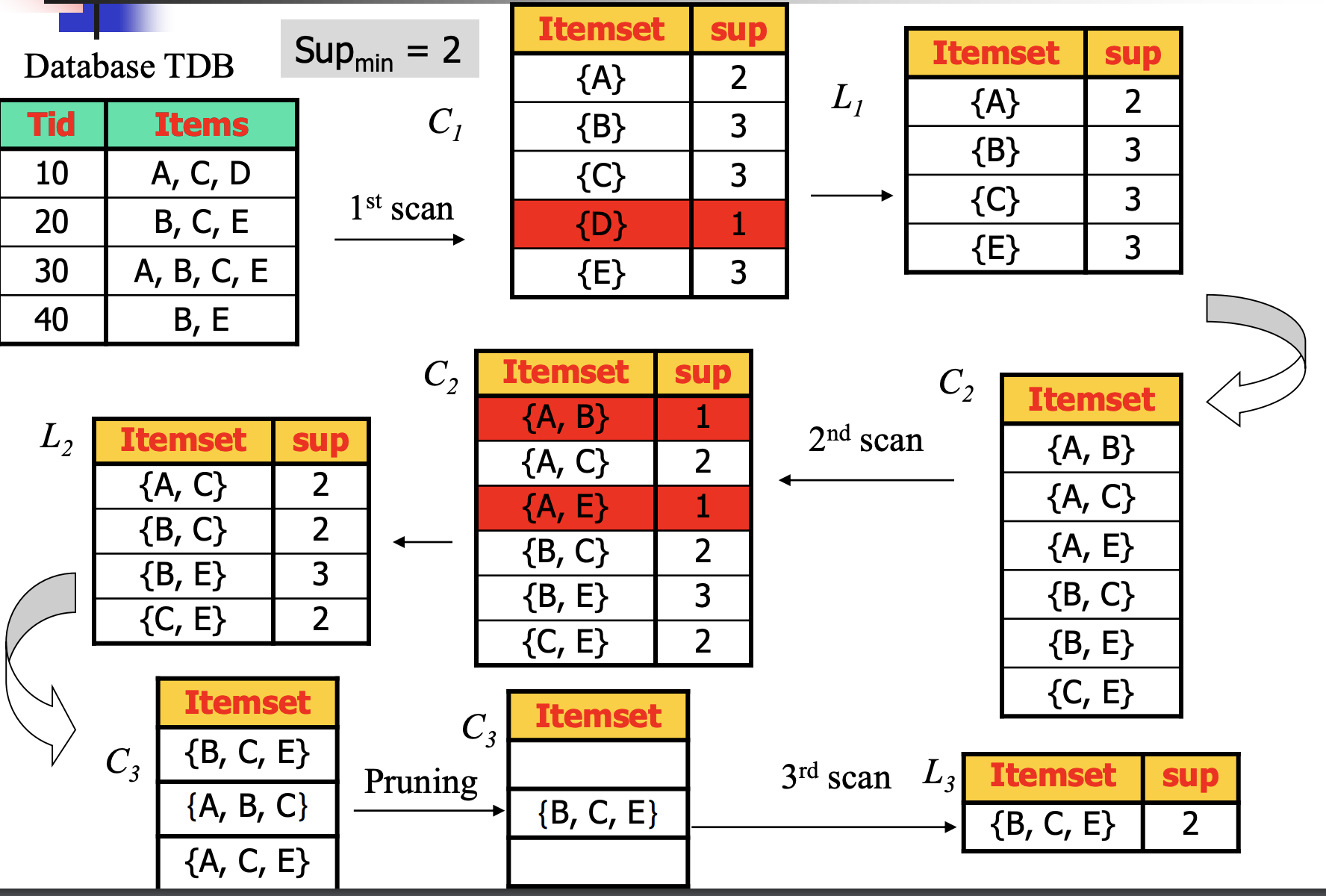
C是生成的可能item,L是所有满足minsup的item组合。
所有的L就是我们要找的满足minsup的item。
问题是怎么生产C呢?
分2步:
- self-join \(L_k\)
- pruning
self-join的例子:
上图的\(L_2 = \{ AC,BC,BE,CE\}\)
第一步:\(L_2 \ join\ L_2 = {ABC,ABE,ACE,BCE}\)
第二步:ABE 会被删掉因为 AE不在\(L_2\)里面,根据Apriori算法,AE不是frequent,它的子类必不frequent。因此ABE会被删掉。
因此我们得到\(C_3 = \{BCE,ABC,ACE\}\)
3. Rule Generation
当我们得到所有满足minSUP的item后,我们还要找到满足minCONF的item,即\(\rightarrow\)该是谁指向谁。
例如当我们知道item{A,B,C,D}满足minSUP,它有以下这么多种可能:

总共会有\(2^{k-2}\)种可能,k为item包含的个数。
对于confidence,我们能找到这样的关系:
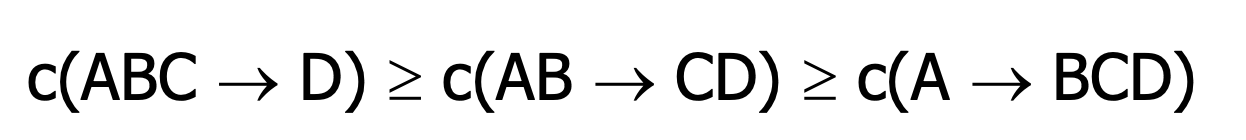
2个关系,左边多数的一定大。
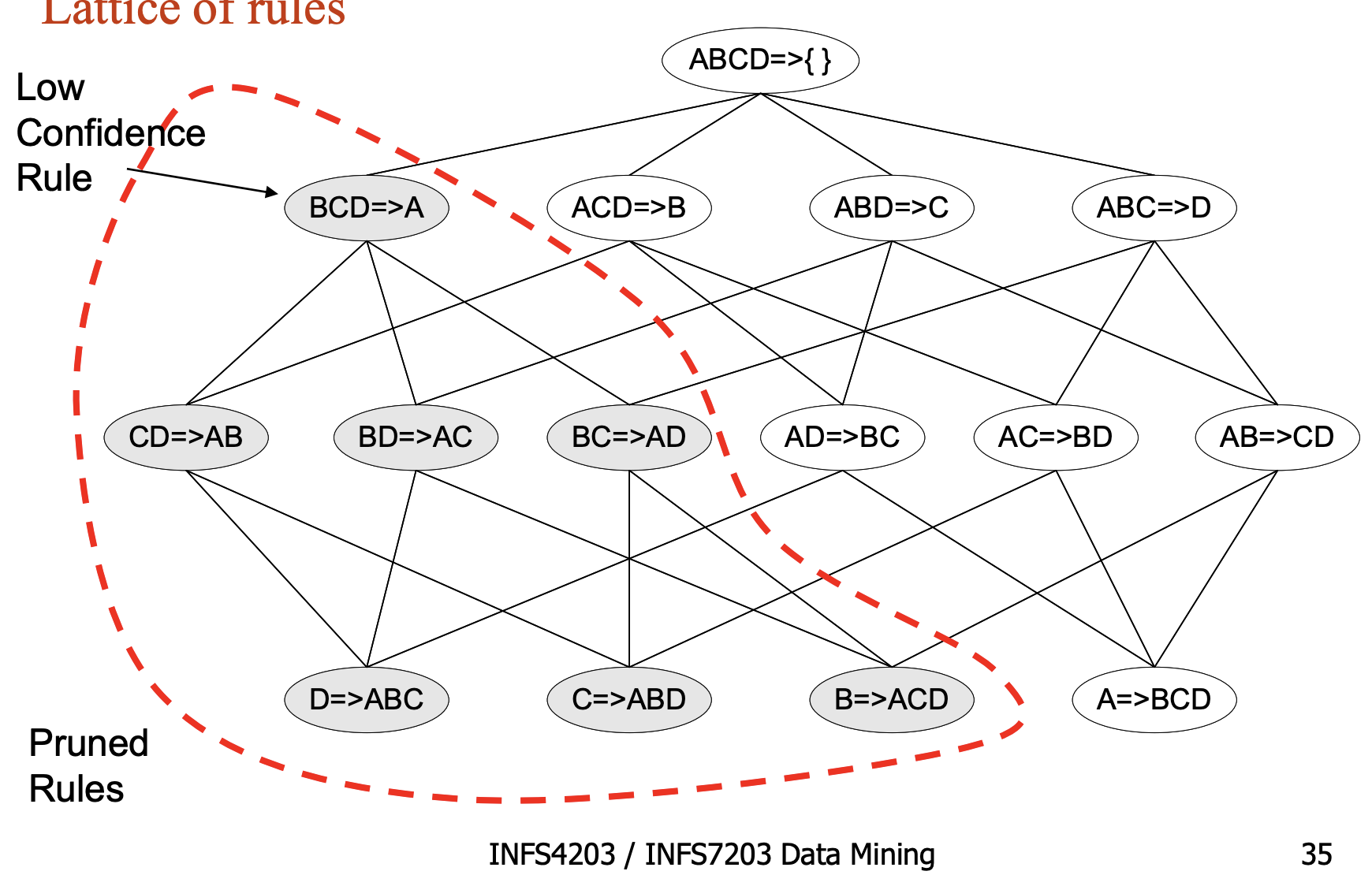
Maximal Frequent Itemset
一个itemset可以被称为Maximal Frequent Itemset当它是frequent并且它的下一层超集不是frequent的。
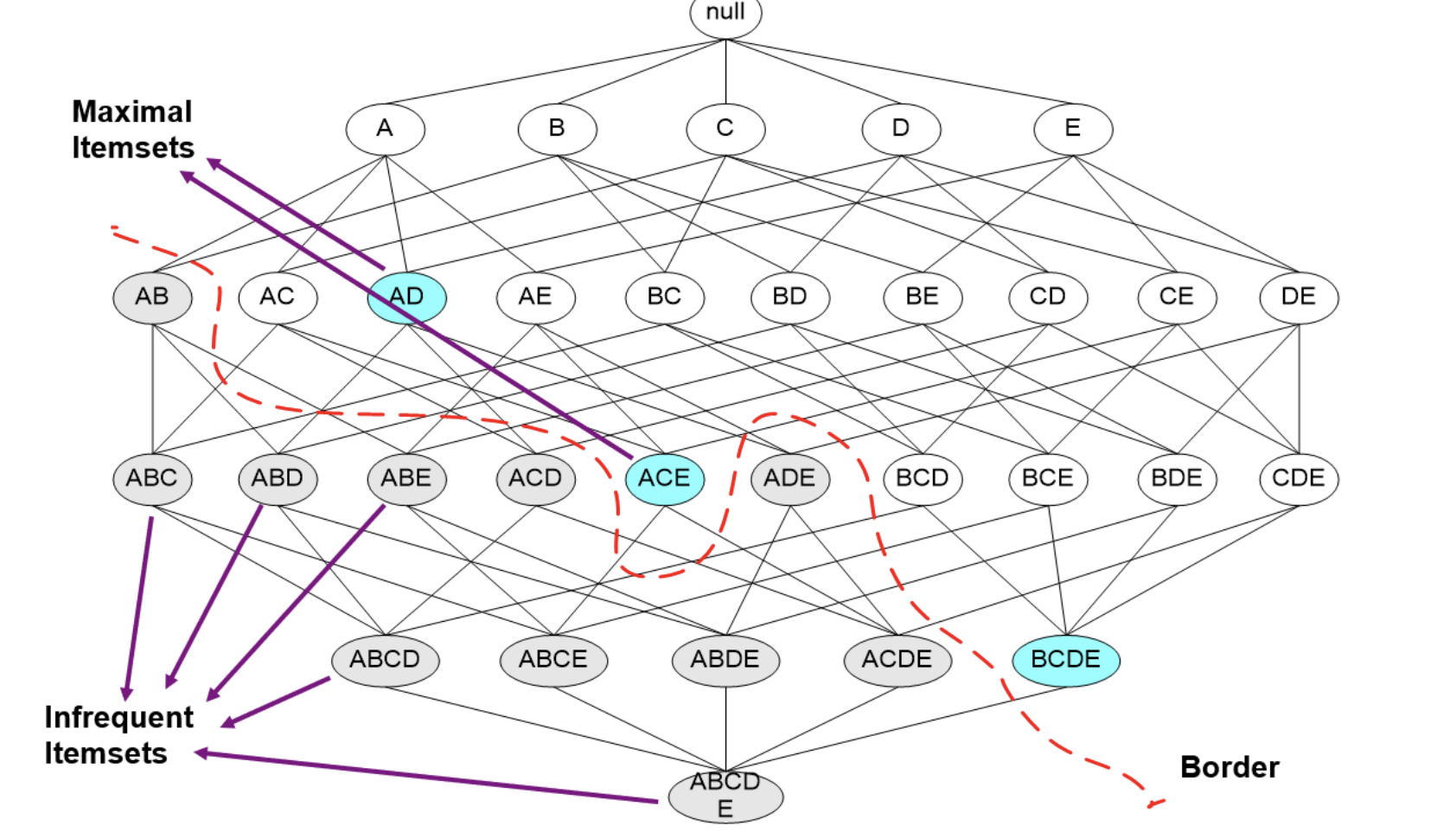
例子:
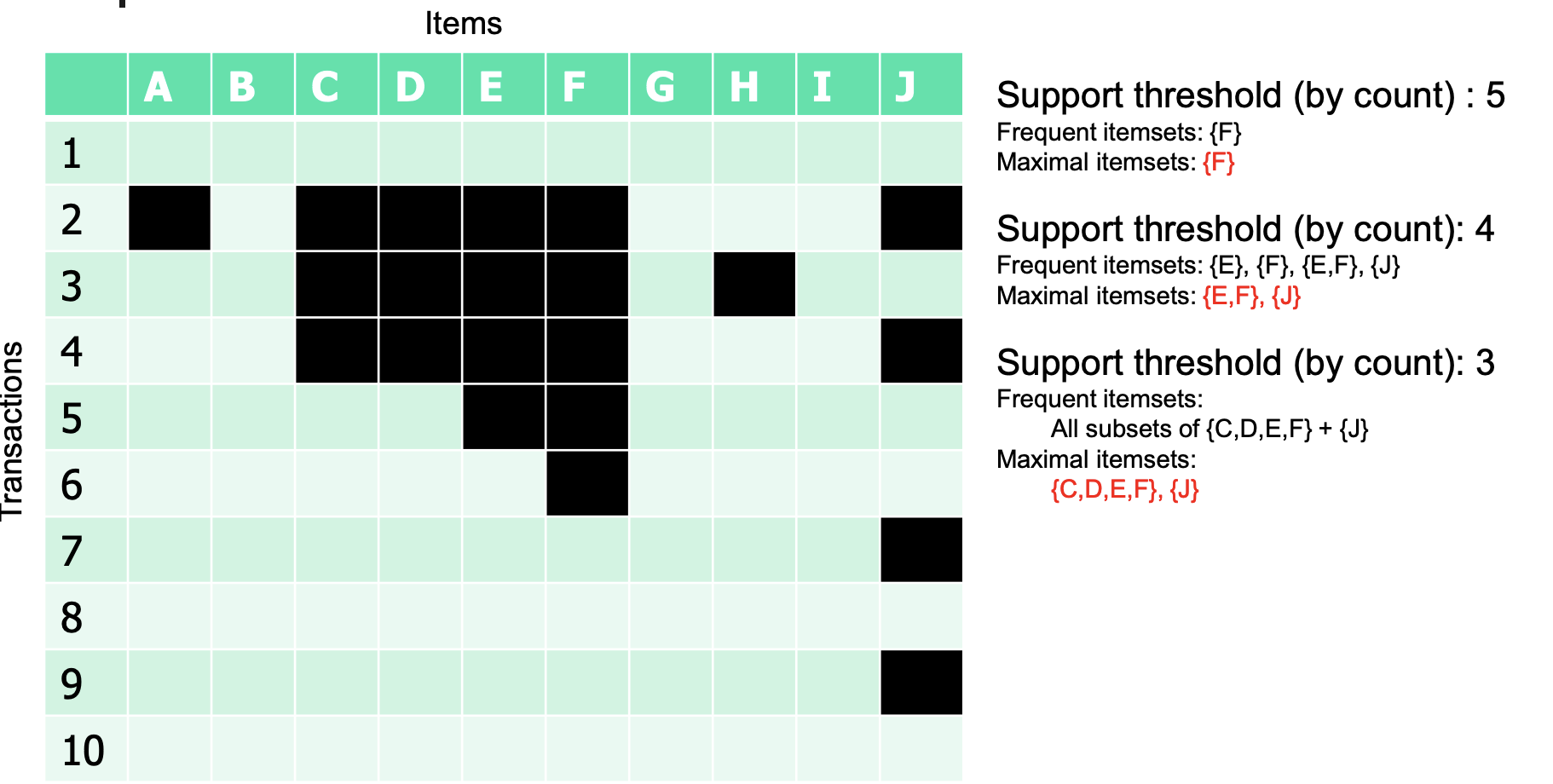
Closed itemset
一个itemset是closed itemset,那么它的immediate superset的supports和它的support不一样。
例子:
我们有这样一个transaction
计算support:
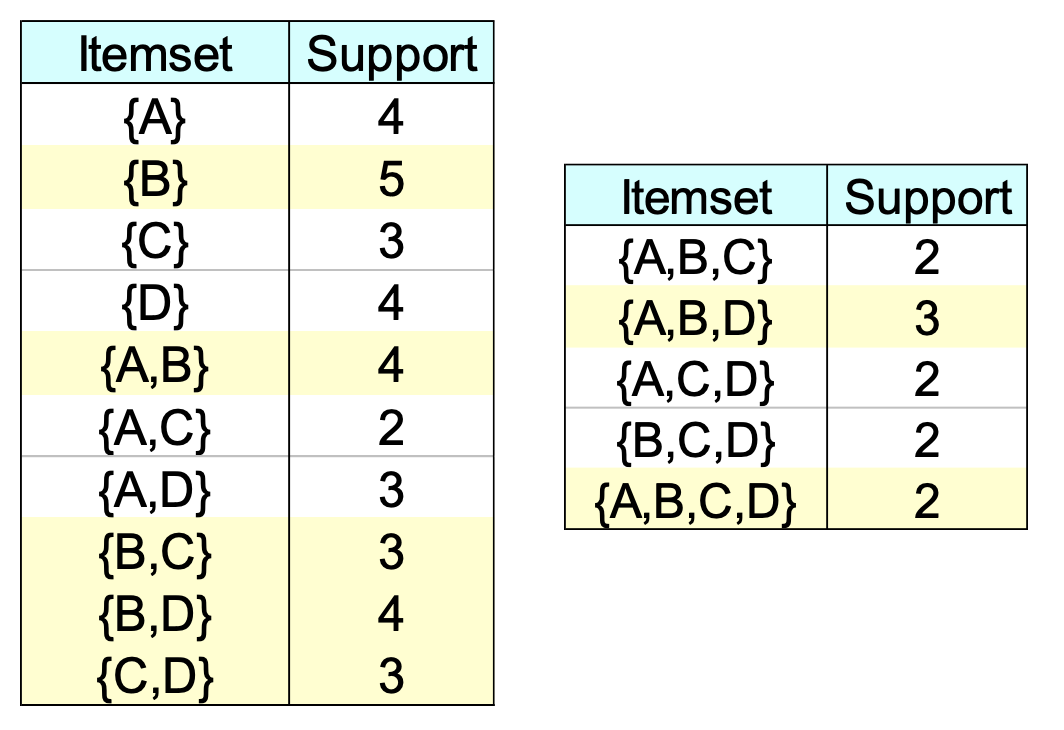
黄色的部分就是closed itemset。
例如我们考虑{B}, S(B) = 5,
B的immediate supersets的support为S(A,B) = 4, S(B,C)=3, S(B,D) = 4
他们都不等于S(B),因此B是closed itemset。
V. Anomaly/Outlier 异常值检测
1. 概念介绍
什么是异常值?
The set of data points that are considerably different from the remainder of the data
与其余数据有显着差异的一组数据点
杠精提问1: 那怎么判断这个数据点是和其他的数据显著差异的呢?
异常值检测可以用在哪?
数据清洗,异常值会造成错误的判断
把找出那个异常值当作目标,例如故障检测,网络入侵检测(因为异常值和正常值有很大的差异,所以它们可能会是故障或者人为故意的行为)
异常值(outlier) 和噪声(noise)是不是一个概念?
不是!
噪声是随机出现的错误。比如你输入的时候打错了字,别人填问卷调查的时候勾错了选项(不是故意的)。
异常值是真实发生的,但是和正常的数据不一样(例如绝地求生开挂的孤儿的数据变态的离谱)。因此,异常值是很有趣的而且有时候可以作为数据挖掘的目的(查出那些开挂的孤儿,再封掉它们)。
总结:
噪声(noise)无论干嘛都是第一个需要被清洗掉的(噪声:我做错了什么)
杠精笑齐:那清洗噪声的方法呢?
(我的想当然:在实际情况中,噪声和异常值在用清洗方法的时候都同时被去掉了。而如果目的是找出异常值的话,在找到异常值和噪声的合集之后,根据业务逻辑来判断。因为噪声都是随机的错误,而异常值是有逻辑的,而且这个合集应该是比较小的,可以单独判断吧。发邮件给老师后的回复:噪声和异常点的区别
异常值(outlier)经常在噪声被剔除后也被删掉,但也有可能项目目的就是检测出异常值。
异常值评估
我们找出来的异常值是正确的,真的的异常值嘛?该怎么评估(evaluate)我这个方法找出来的异常值好不好?
很难界定,因为我们不知道正确答案啊。异常值检测也是无监督学习,他的评估和聚类(clustering)类似。
异常值检测方案(schema)
顾名思义,首先定义出正常的值(大部分的数据)。然后和我们定义的正常值有显著差异的值就是异常值了嘛。
异常值类型
全局异常值(Global outlier):这个点和绝大多数正常值都有显著差异。(其实就是定义,最土味,最直观的,也是大多时候我们所要找的异常值)
Contextual outlier(上下文异常值?没找到专业的中文名词):这个点和特定的上下文数据有显著差异。
一个方便理解的例子:今天温度40度,我们一般的天气20多度或者30多度。如果用全局异常值的方法,可能这个40还是包括在正常的浮动范围里的,但是40度是非常恐怖的天气,一定是算异常值的。这时候我们就要结合我们的上下文,即我们是在什么时间段?什么地点? 等等上下文因素去考虑异常值。
集体异常(collective outlier):单个的数据不是异常值,但是多个个体一起出现时一种异常。
某一户小区有一户人家搬走了,不是异常。十户人家一起搬走了,是一个异常。
一台电脑拒绝发送请求,可能突然fail了,不是异常。十台电脑拒绝发送请求,是异常,可能被黑客攻击了。
FPX的5个人每个人都不是变态强的选手,不是异常。5个人组合在一起贼猛,成第一名了是异常。
举例子实在太好玩了。
2. 异常值检测的各种方法(Anomaly Detection)
1.统计检验(Statistical-based)
- 假设这个数据集是根据一种随机过程(stochastic process) 产生的。就是说服从某种模型(例如正太分布)。
- 用各种数据拟合(data fitting)的方法,例如最小二乘,梯度下降,把这种分布表示出来,然后处于低概率的那些数据点就是异常值。
有参数模型
假设这个数据集服从某种概率密度函数,例如我们假设数据集是服从我们最喜欢的正太分布。

它需要参数:平均值,方差
根据这个图我们知道,当我们的数据是在这个图里左右2.5%的时候,数据是异常值。
杠精笑齐:那到底咋算啊? 参数咋算啊??这个2.5%又是什么东西啊???
正太分布的公式是这样的: \[g(x)=\frac{1}{\sigma \sqrt{2 \pi}} e^{-\frac{1}{2}((x-\mu) / \sigma)^{2}}\]
其中\(\mu\)是我们数据集的平均值,\(\sigma\)是我们数据集的方差,这2个就是我们这个方法需要的求的参数!
2.5%不用管,有兴趣的可以去学习统计——概率密度函数。
但是根据经验表明,\[ \mu \pm 3\sigma\] 这一段数据在正太分布里可以涵盖99.7%的数据。
所以我们就计算:\[ \mu \pm 3\sigma\] ,只要我们的值 $ x < - 3$ 或者 $ x > + 3$ ,那x就是异常值!
这里直接把书中的例子搬过来:
我们有一个数据集是{\({24.0, 28.9, 28.9, 29.0, 29.1, 29.1, 29.2, 29.2, 29.3, 29.4}\)}, 并且我们知道它是服从正太分布的。(要好多假设条件😀)
我们就能求出来: \(\hat{\mu}=28.61 , \hat{\sigma}=\sqrt{2.29}=1.51\)
那\[ \mu - 3\sigma = 24.08\],\[ \mu + 3\sigma = 33.14\]
大功告成,我们发现只有 24 是在这个区间外面的,所以24就是这个数据集的异常值!Bingo😉~
总结一下哈:这个方法要求的条件也太多了。
- 第一要求数据集服从一种模型。实践中我们拿到一个数据集,这个数据集又不会告诉我们它是属于什么模型,什么概率分布的。
- 第二绝大多数只能应对一维的情况,就像我们的例子。但是实际操作我们的数据集特征都是少说也有十几个吧(年龄,性别等等)。对于一个高维的数据集,我们是很难去估计它服从什么分布的。(我不知道为什么,但是这学期的数学课推了一个二维的正太分布就挺复杂了,而且已经是三维的图了。所以这里只记了结论)
无参数模型
我们想用一个概率分布去表达一个数据集的目的其实是为了找到数据集的正常值(normal data)。但是其实我们可以靠目测(听上去更加不靠谱)。就是我们识别这个正常值不用一个先规定好的结构/模型。
那我们用什么来预测?(都轮不到杠精笑齐来提问的问题) 用土味的histogram(直方图)
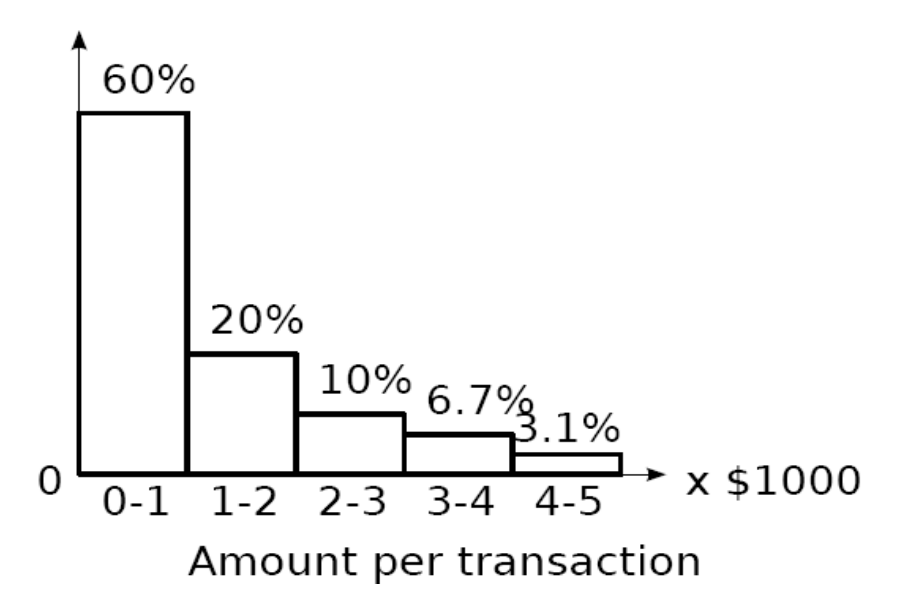
假设这是一张交易记录的直方图,我们规定了bin(直方格)的长度是1。然后就出来了这个图。然后我们发现只有0.2%的交易是大于5000的。那所有在这个交易记录里面大于5000的都是异常值了。好简单好爽好快乐。
杠精笑齐:那这个bin咋算??我要是算bin是0.5一格的话,那是不是有可能5500以上的才是异常值啊?那我前面好简单好爽好快乐的方法说5100是异常值,这个又说5100不是异常值?你这个人靠不靠谱啊??
所以这个方法我觉得应该也算是有参数的,参数就是bin的取值。
bin取值带来的问题:
bin值太大:那就会让有的异常点跑到正常值里面去了。想象一下我们只有一个bin(这个bin值就是全数据集的长度),这个bin的频率是100%,异常值都跑到bin里面去了。false negative
bin值太小:那我们的正常值可能会被判断成异常值了,想象一下我们有N个bin(N就是我们数据集的长度),这样我们每个数据点的频数都是1,频率都是一样且非常小,那每个数都是异常值了。false positive
这里的false negative和false positive是第一张分类混淆矩阵(confusion matrix)的知识内容,被混淆了的同学请前往混淆矩阵。
2. 接近度(Proximity-based)
1. 基于距离(distance)
直接给出公式
\[ {\frac{\left\|\left\{o^{\prime} | \operatorname{dist}\left(o, o^{\prime}\right) \leq r\right\}\right\|}{\|D\|} \leq \pi}\]
好懵逼🤣,没事。
原理就是
- 你自己定义一个距离。
- 然后计算所有数据点和现在在判断是不是异常值的这个数据点的距离。
- 数出有多少个点是在你自己定义的距离里面的,就是步骤2的距离小于步骤1的距离。
- 把步骤3数出来的数除以数据集的长度(有多少个数据点),如果小于一定的比例,就是异常值。
还是好懵逼🤣
首先 \(\pi\)和\(r\) 是我们自己设计的值。\(r\) 就是步骤1的距离。$ $ 不是那个3.1415……,是步骤4的那个比例,也是一个我们设计的0到1之间到百分数。\(o^{\prime}\) 代表所有其他数据点。
$ {O^{} | (O, O^{}) r}$ 代表步骤2 ,\(\|D\|\) 和分子的 ||…|| 都代表cardinality(基数),就是有多少个,步骤3和步骤4
应该懂了,在加深一下,所以我们可以定义 \(k=\pi\|D\|\), 那k其实也代表一个threshold(阈(yu)值),它的意义是如果你步骤3数出来的基数(个数)少于 \(k\) 的话,这个值就是异常值。
现在考虑一下优化方法,作为一个未来的数据科学家,经常处理特别大的数据集,不学优化等于每一次调试都要等很久或者想要买一台新的电脑
优化: 如果步骤3已经数到了\(k\)个值,就停止循环。(没必要继续继续下去了,这个数据集已经证明自己不是异常值了,我们不需要知道它有多靠近数据集的中心)
2. 基于密度(Density-Based Outlier Detection)
不像上一种方法用一个数据值和所有其他数据值比较,我们只比较和它相邻的数据。
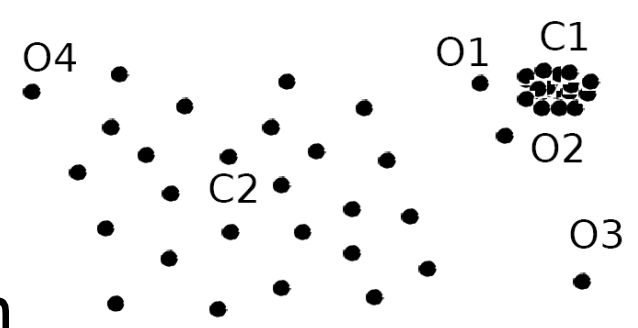
如图,根据不靠谱的目测,我们觉得
\(O_1,O_2\)是\(C_1\)的异常值,\(O_1,O_2\)就是局部异常值(只针对\(C_1\))
\(O_3\)是全局异常值
\(O_4\)是正常值,不是异常值。
但是,试想一下我们用前面的一种检测方法(基于距离),我们是找不到\(O_1,O_2\)是异常值的。(因为它们离\(C_1\)其实挺近的。)
但是基于密度的方法我们是可以找的。
这个方法课件里面说是用最低的LOF值,tutorial里说用最高的LOF值是异常值,把我搞混了很久,老师回复邮件后搞懂。
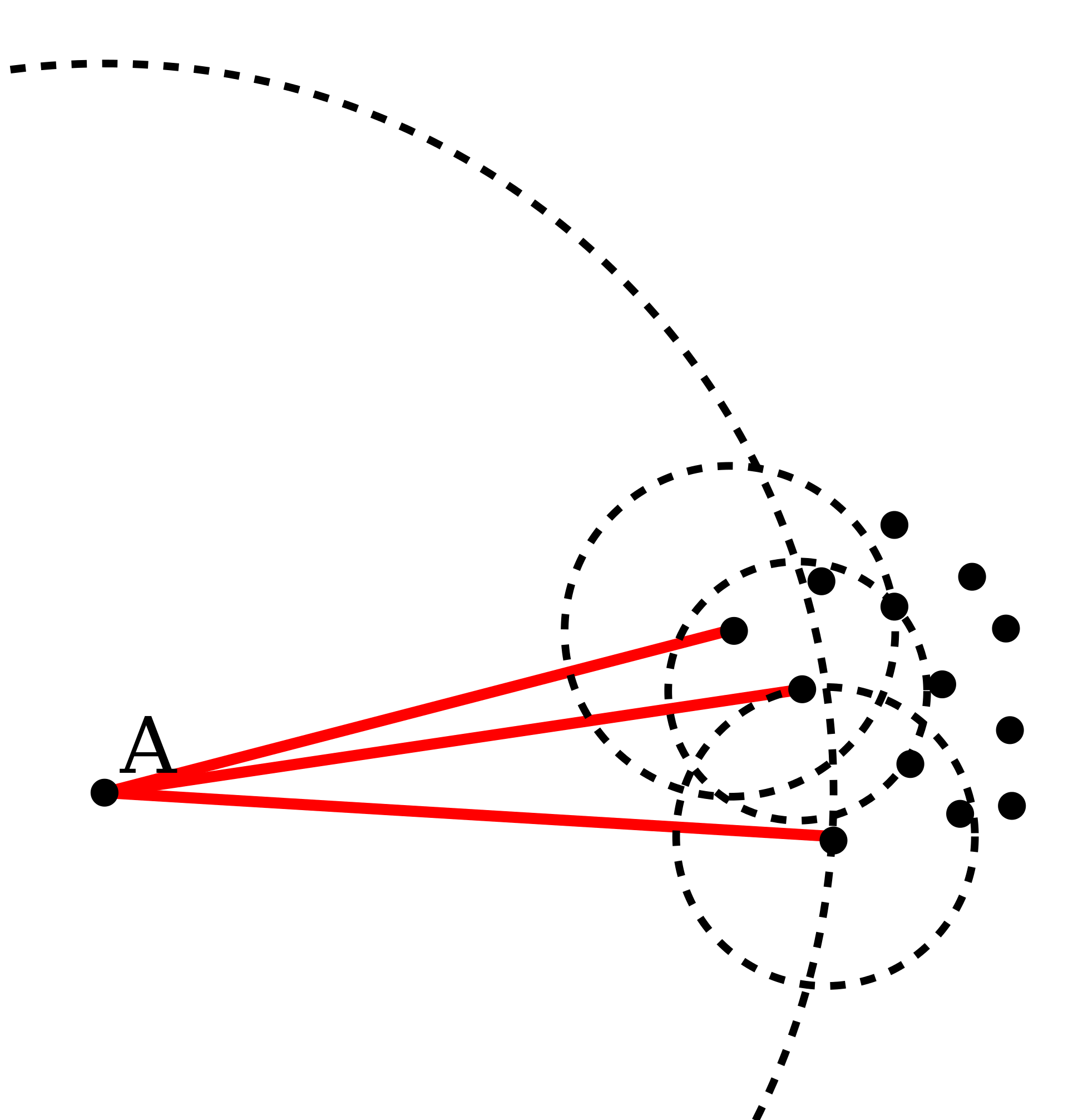
基本思想:比如我们检测A是不是一个异常值,我们是比较A的密度和A密度范围里面其他点的密度的平均值。
怎么比呢?就是用它们的比值,它有一个特别的名字(LOF: Local outlier factor)。
这里分子是范围内点们密度平均值,分母是A的密度
- 如果这个比值接近1: 说明A的密度和它范围内的点们的密度都差不多,那就说明不是离群点了。
- 如果这个比值小于1: 说明A的密度比范围内的点们大,A更靠近它们。
- 如果这个比值大于1: 说明A的密度比范围内的点们的密度平均值小,A是异常值。
杠精笑齐:
这个范围是怎么定义的?为什么图里面A的范围那么大,在A范围里的那3个点的范围那么小?
这个密度是从哪里冒出来的,咋算啊?
范围:离要检测的点最近的第K个点的距离是这个检测的范围。
图中我们选的\(K=3\), 所以A里面包含了3个点,其他的点的范围也都是3个点。
这样就避免了我们基于距离方法的问题,我们现在定义的距离是动态的,是能根据不同的点来变 换的。
密度:其实更具体的名词是局部可达性密度(lrd)
密度等于质量除以体积 —— 不是你想的那样。 但是核心思想差不多啦,就是我们想知道在这个检测点密不 密集。但是这个事情是非常难用数学表达出来的(对我们学渣还非常难理解😱这么多数学符号是什么鬼 啦,为了让大家查阅其他资料的时候符号一样,下面我也被迫使用这么多不想看明白的数学符号)。
质量:是我们的规定的K。图中的例子就是 \(3\).
很多用\(|N_{k}(A)|\)表示,其中\(N_{k}(A)\) 就是被A的范围包含的点们的集合。\(|x|\)代表x的基数(个数)。
明明就是 K嘛,为什么要这么复杂。。。要是我理解错了请告诉我。
为什么要用K呢,因为这样我们所有的点的分子都是一样的了,看它们密不密集,就看分母了。
体积: 是我们\(N_{k}(A)\)里所有点到A的距离和。
然而距离不是单纯的距离,有一个新的距离定义方式叫可达距离
reachability-distance \(r-d(A,C) = max(k-distance(C),d(A,C))\)
\(k-distance(C)\)是C的范围。
也就是当我们算A范围里其他点(例如C)对A的距离的时候,这个距离至少得是C的范围。
(其中理论我也没懂,求大神解释)
密度计算公式:
\(\operatorname{lrd}_{k}(A):= \frac {|N_{k}(A)|}{\sum_{B \in N_{k}(A)} {reachability-distance}_{k}(A, B)}\)
分子就是我们说的质量嘛,分母就是我们说的体积嘛。
终于到LOF了,现在我们再来看我们的基本思想:比较A的密度和A密度范围里面其他点的密度的平均值。
我们已经会求密度了,直接看公式:
\(\operatorname{LOF}_{k}(A) = \frac{\sum_{B \in N_{k}(A)} \operatorname{lrd}(B)}{\left|N_{k}(A)\right|} / \operatorname{lrd}(A)\)
左半部分A密度范围里面其他点的密度的平均值,右半部分A的密度
现在也很好理解为什么tutorial里面说高的LOF值是异常值,课件里面说低的LOF值是异常值了。
因为它们的比值分子分母反了。。。分子分母反了。。。反了。。。
为了应付考试的步骤流程图:
- 根据题目给的K值和定义距离的方法(曼哈顿,欧几里得)找出每个点的k-distance(范围)
- 找出每个点里面k-distance(范围)里面的其他点
- 计算所有点的密度
- 计算每个点的LOF
- 看你怎么比决定取最大值还是最小值作为异常值。
(终于完了,唯一一个疑惑的就是可达距离的含义了)
总结:
基于距离:异常值的附近不够满足你要求的点的数量。
基于密度:异常值的密度不够满足你要求的密度。
3. 聚类检验(cluster-based)

看图就明白了,把数据集用某种聚类方法聚类。
1.这个点到属于它的类的类中心的距离非常的长
2.包含很小数量的聚类都是异常值。
第一种情况:
那我们就计算这个点\(o\)到类中心\(c\)到距离\(d(o,c)\),和其他属于这个类的点们\(o_i\)到类中心\(c\)的距离平均值\(d(o_i,c)_{avg}\),然后计算它们的比值,如果这个比值很大,说明这个点\(o\)就是异常值。 用比值的原因就是给我们一个关于这个类本身大小的判断依据,不然有的类很大,有的类很小。如果只根据距离定义阈值会出现错误。
第二种情况:
假设有一个数据点\(p\)
如果\(p\)在一个比较大的聚类\(c_1\)里面:
\(CBLOF = c_1的size \times p和c_1的相似度\)
如果\(p\)在一个比较小的聚类\(c_2\)里面:
\(CBLOF = c_2的size \times p和离它最近的大聚类的相似度\)
相似度有很多种不同的方式。CBLOF比较小的值就是异常值。 (2个参数,相似度低或者类比较小,就代表离群了)
VI. Recommender Systems
1. User-based
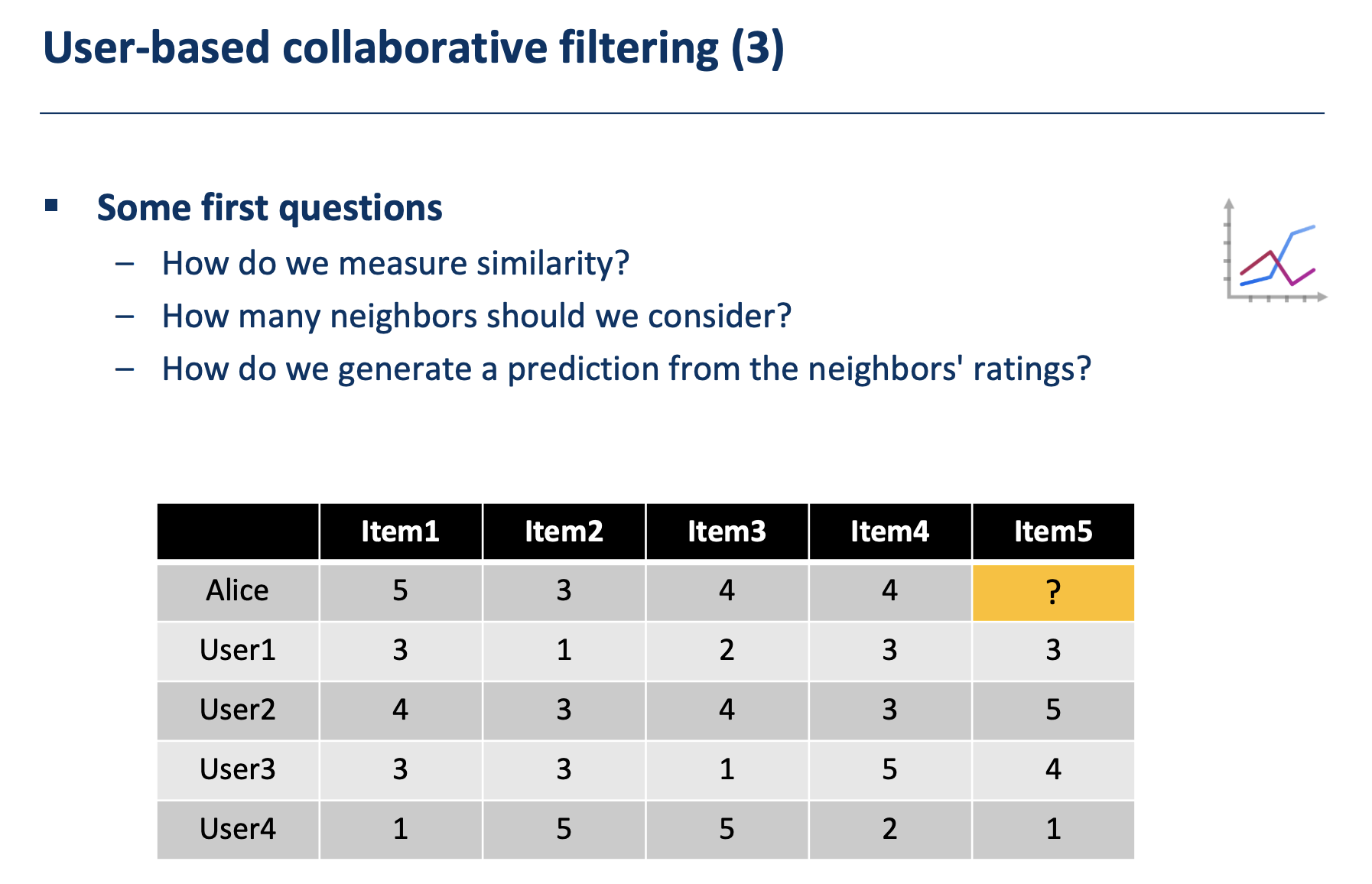
Pearson correlation
使用pearson相关系数来作为相似度的考量

其实和我们介绍过的cosine similarity非常相似:
在cosine similarity中:$ (a, b)=$
上面就是两条向量的点积,下面是各自向量的模
而pearson这个人就是把cosine similarity做了个中心标准化(每一项都减去平均值),就像正太分布变成标准正态分布一样。
例子:计算Alice对于“Item5”可能的评分(兴趣)是多少?
思路:
- 计算Alice和所有其他user的similarity
- 根据你选用的neighbor策略(选k个相关的user作为参考)选相似度最高的k个user
- 根据那k个uesr的item5评分,计算\(\operatorname{pred}(\boldsymbol{a}, \boldsymbol{p})=\overline{\boldsymbol{r}_{a}}+\frac{\sum_{b \in N} \operatorname{sim}(\boldsymbol{a}, \boldsymbol{b}) *\left(\boldsymbol{r}_{b, p}-\overline{\boldsymbol{r}}_{b}\right)}{\sum_{b \in N} \operatorname{sim}(\boldsymbol{a}, \boldsymbol{b})}\)
计算:
- \(\hat{Alice}=4,\hat{user1}=2.25\), 注意这里user1的平均值不包括item5,后面的计算也不包括,item5的值仅在预测那一步使用),\(sim(Alice,user1) = \frac{(5-4)(3-2.25)+(3-4)(1-2.25)+(4-4)(2-2.25)+(4-4)(3-2.25)}{\sqrt{(5-4)^2+(3-4)^2}\times \sqrt{(3-2.25)^2+(1-2.25)^2+(2-2.25)^2+(3-2.25)^2}}= 0.85\)
- 同理可得\(sim(Alice,user2) = 0.7\), \(sim(Alice,user3) = 0\), \(sim(Alice,user4) = -0.79\)
- 我们选用2-nearest neighbours: user1和user2
- \(Pred(Alice,item5) = \hat{Alice} + \frac{sim(Alice,user1)*(user1.item5-\hat{user1}+sim(Alice,user2)*(user2.item5-\hat{user2})}{sim(Alice,user1)+sim(Alice,user2)} = 4+\frac{0.85\times (3-2.25)+0.7\times(5-3.5)}{0.85+0.7} = 5.08\)
Peason correlation的缺点
- 并非所有邻居的评分都同样“有价值” –就普遍喜欢的商品达成协议并没有像对有争议的商品达成协议那样内容丰富 –可能的解决方案:对具有较大差异的项目给予更多权重
- 共同项目数的值 –同时考虑皮尔逊相似性和共同评定项目的数量
- 案例放大 –直觉:给予“非常相似”的邻居更多的权重,即相似度值接近1的邻居。
- neighborhood选择 –使用相似性阈值或固定数目的邻居
2. Item-based
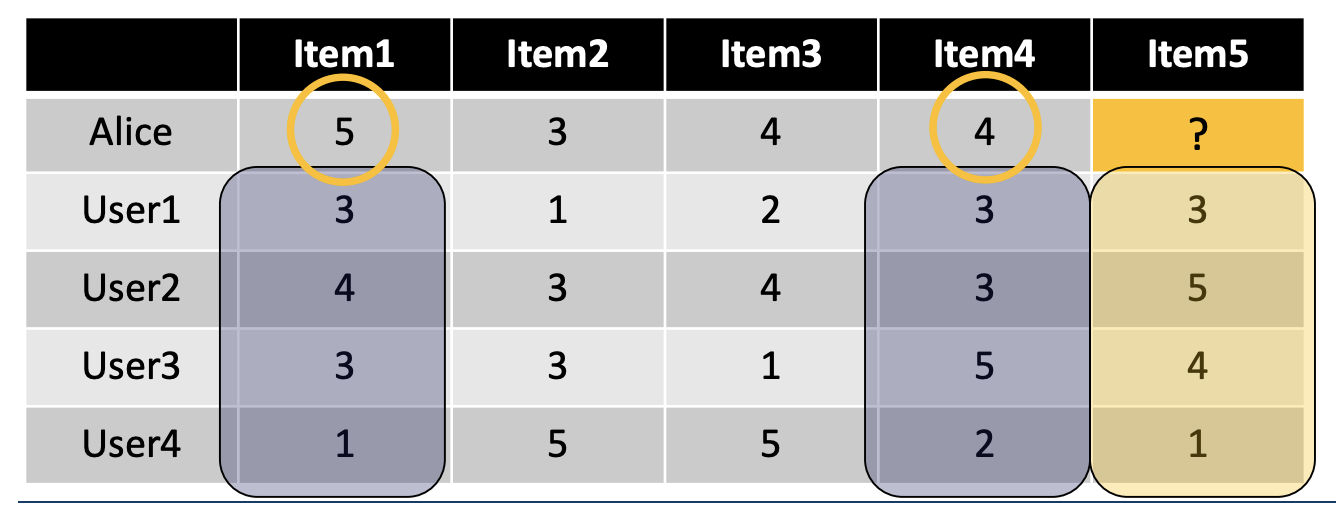
简单的说就是user-based就用user向量(行向量),item-based就是用item向量(列向量)。
3.Latent Factor Model(LFM)
我们将传统的用户/商品表格,转变为“商品-商品属性”与“商品属性-用户喜好”2个表格
即如下格式:\(A_{m \times n}=U_{m \times k} V_{K \times n}\)
我们有如下原始表格(0表示没有评价,需要我们预测)
我们想得到矩阵U和矩阵V,就是构造函数然后使loss function(损失函数)最小即公式:
\(J(U, V ; A)=\sum_{i=1}^{m} \sum_{j=1}^{n}\left(a_{i j}-\sum_{r=1}^{k} u_{i r} \cdot v_{r j}\right)^{2}+\lambda\left(\sum_{i=1}^{m} \sum_{r=1}^{k} u_{i r}^{2}+\sum_{j=1}^{n} \sum_{r=1}^{k} v_{r=1}^{2}\right)\)
等式右边的第一项就是我们的损失函数,第二项是L2正则化项(对应于redge回归的正则化),可以降低解决过拟合问题导致分解后的矩阵元素太大(背就完事了)
对我们的构造函数求梯度:
\(\left\{\begin{array}{l}{\frac{\partial J(U, V ; A)}{\partial u_{i r}}=-2\left(a_{i j}-\sum_{r=1}^{k} u_{i r} v_{r j}\right) \cdot v_{r j}+2 \lambda u_{i r}} \\ {\frac{\partial J(U, V ; A)}{\partial v_{r j}}=-2\left(a_{i j}-\sum_{r=1}^{k} u_{i r} v_{r j}\right) \cdot u_{i r}+2 \lambda v_{r j}}\end{array}, 1 \leq r \leqslant k\right.\)
然后因为数据量过大所以选用SGD(随机梯度下降法,Stochastic gradient descent)
求得U和V矩阵后相乘,可以发现所得结果接近原矩阵,并且原先为0的点有数值了(即预测值)
LFM的优点:
- high accuracy
- Auto group items –
- Scalability is good –
- Learning-based
缺点:
- Incremental updating
- Real-time –
- Explanation
4. Model-based
用我们前面学过的各种模型来进行对rating的预测
1. Bayes
例如我们有这样一个表:
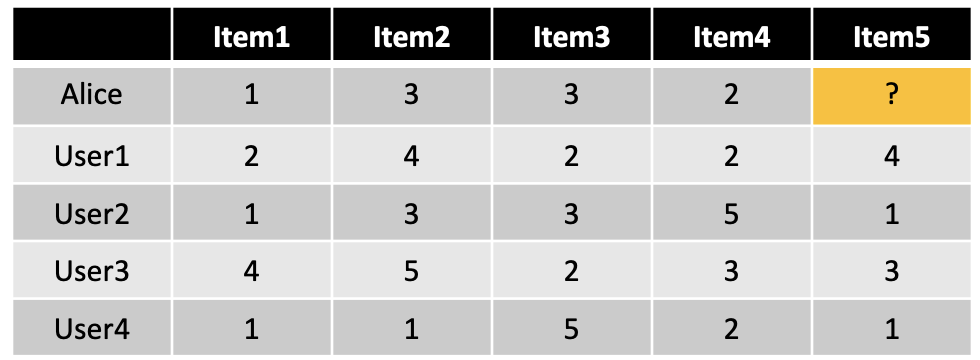
计算\(P(Item1 = 1, Item2 = 3, Item3 =3, Item4 =2|Item5 = 1)\)
\(P(Item1 = 1, Item2 = 3, Item3 =3, Item4 =2|Item5 = 2)\)
\(P(Item1 = 1, Item2 = 3, Item3 =3, Item4 =2|Item5 = 3)\)
\(P(Item1 = 1, Item2 = 3, Item3 =3, Item4 =2|Item5 = 4)\)
\(P(Item1 = 1, Item2 = 3, Item3 =3, Item4 =2|Item5 = 5)\)
选最高的概率