This article decribes an end-to-end framework for contrastive learning called SimCLR.
Paper: Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations. arXiv:2002.05709, 2020. Updated version accessed at: https://arxiv.org/abs/2002.05709.
Bottleneck of past work
Although InstDisc which we talked in the last chapter proposed a nice pretext task which makes self-supervised learning seems possible in CV field, the accuracy/performance of InstDisc on image-net is not high, which means that the representation learning from InstDisc is not good.
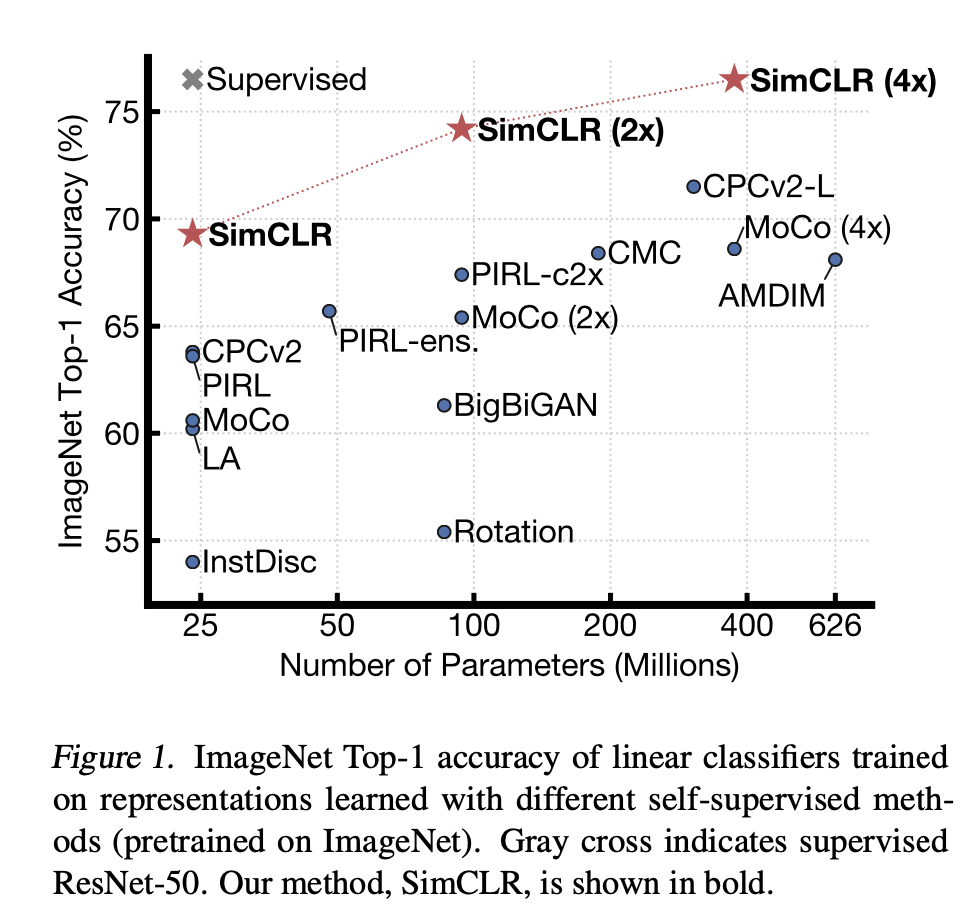
Unlike other CV papers that put network structure or images in Figure 1, Figure 1 in simCLR just want to tell people that how good performance simCLR is. Actually, as the name of the paper defines, this is a very simple framework, but it is the first time that unsupervised learning can beat the benchmark supervised model on image-net, which demonstrates the power and confidence of unsupervised learning.
Model Framework
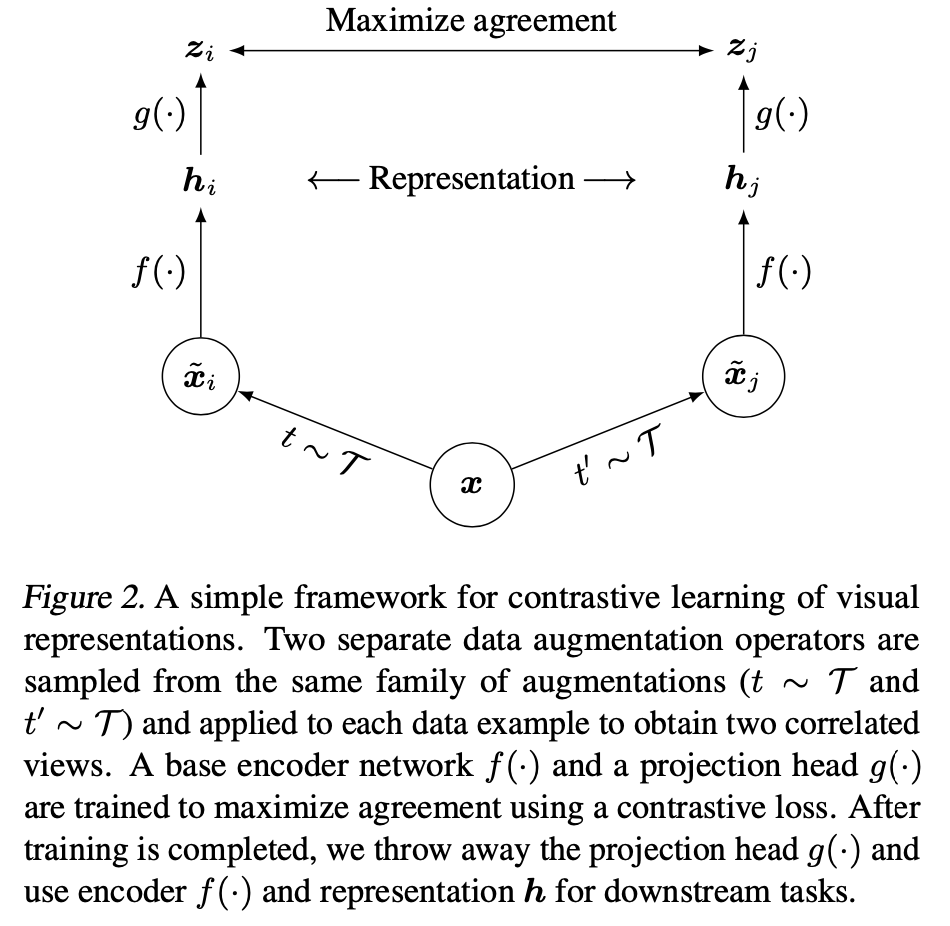
If Figure 2 is hard to understand, here is a structure drawn by me.
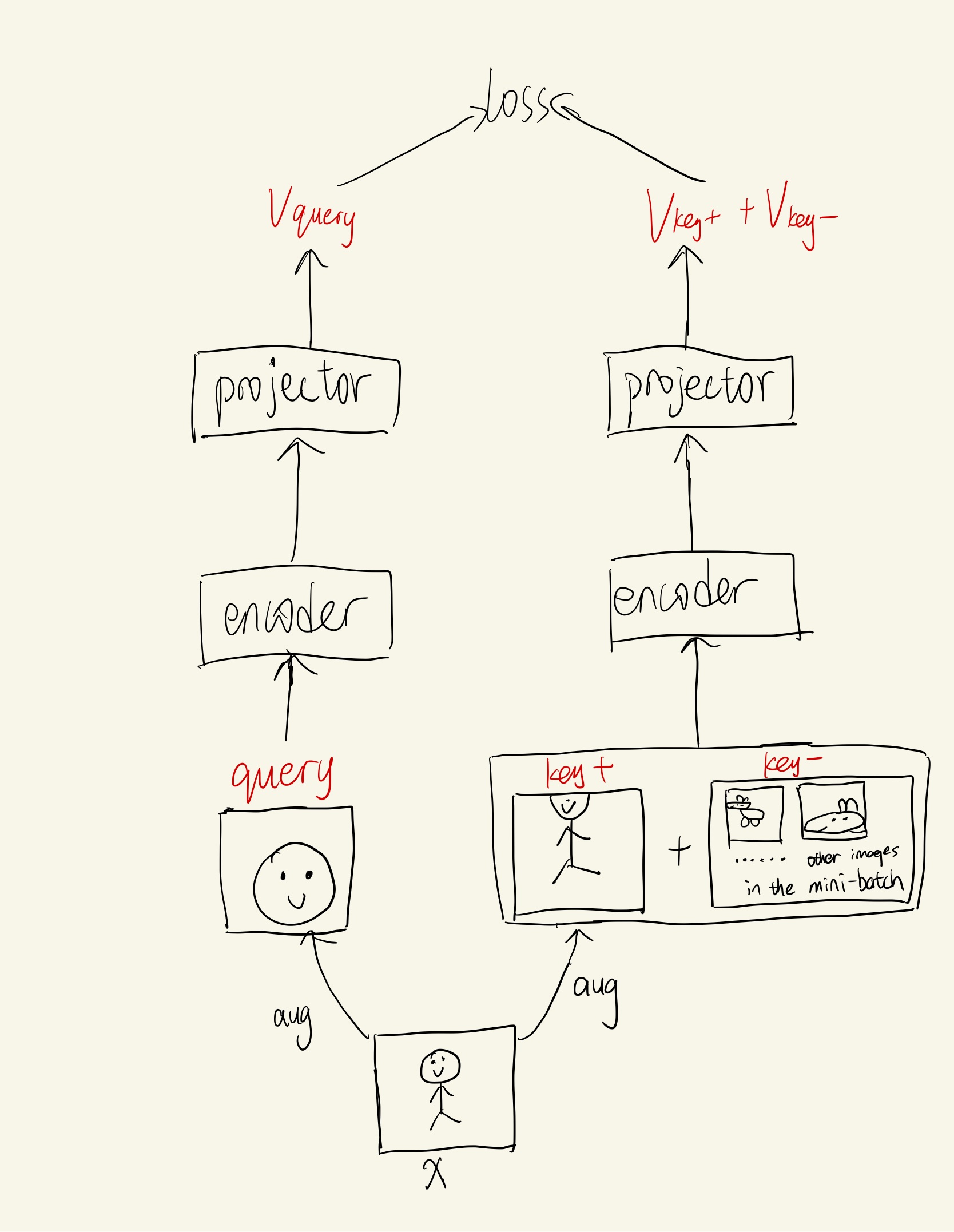
The difference from InstDisc to simCLR is that it straightly uses images in the same batch as negative samples instead of using memory bank. In this way, all image vectors are obtained from the same encoder every time, which naturally solves the problem of inconsistent feature distribution in InstDisc.
Model Insights
- Composition of multiple data augmentation operations is crucial in defining the contrastive prediction tasks that yield effective representations. In addition, unsupervised contrastive learning benefits from stronger data augmentation than supervised learning.
- Introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations.
- Representation learning with contrastive cross entropy loss benefits from normalized embeddings and an appropriately adjusted temperature parameter.
- Contrastive learning benefits from larger batch sizes and longer training compared to its supervised counterpart. Like supervised learning, contrastive learning benefits from deeper and wider networks.
These 4 insights are the most important essence of this paper. We will discuss in detail one by one.
Data augmentation
The first insight demonstrates that data guamentation is an important condition for a successful training in contrastive learning.
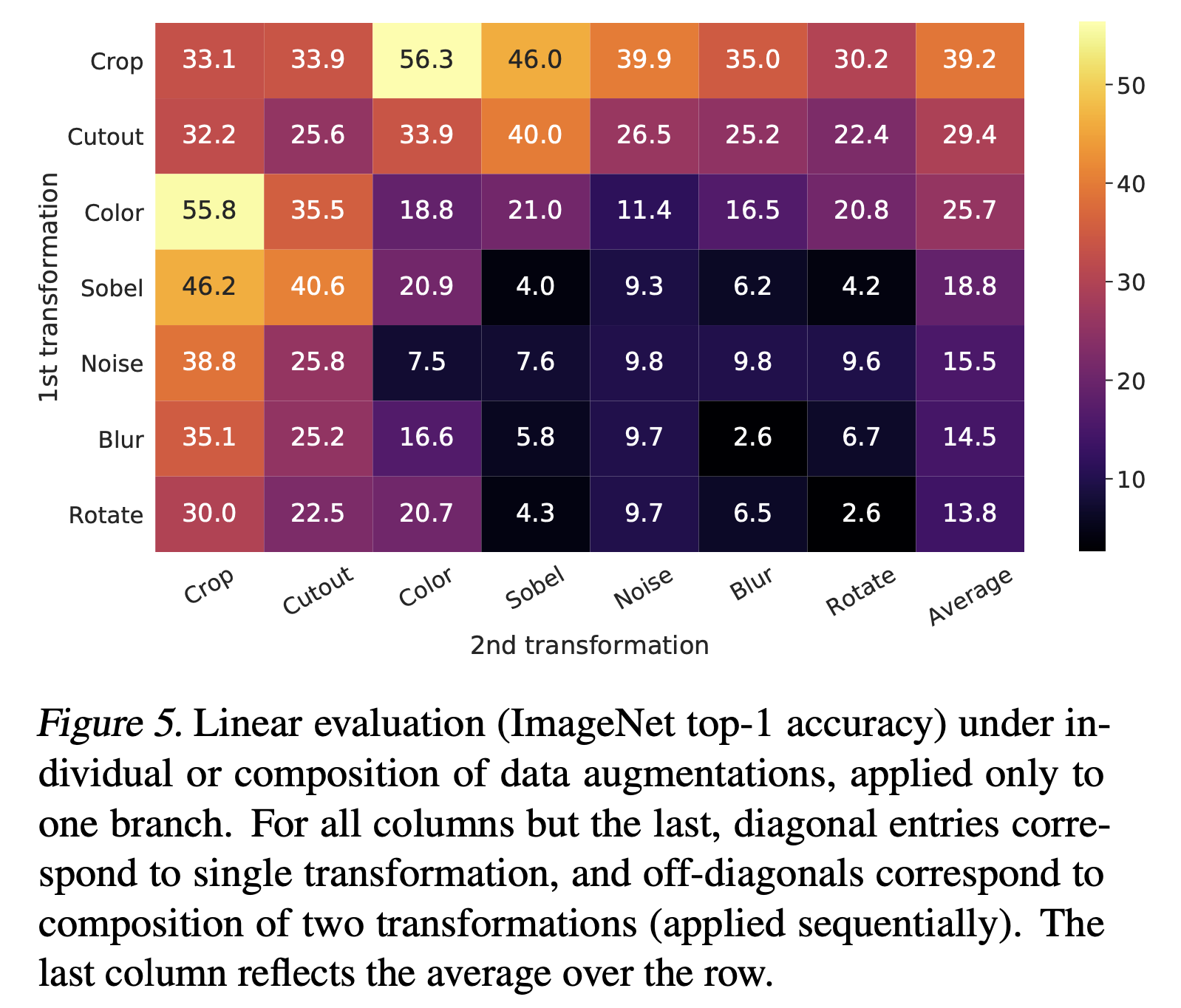
Figure 5 shows that the combination of random cropping and random color distortion is the best data augmentation for improving accuracy. This result makes almost all subsequent comparative learning work use this data augmentation strategy.
Moreover, it conjectures that:
one serious issue when using only random cropping as data augmentation is that most patches from an image share a similar color distribution. Neural nets may exploit this shortcut to solve the predictive task. Therefore, it is critical to compose cropping with color distortion in order to learn generalizable features.
The original paper shows very detailed augmentation strategy and experiment results to prove this point in chapter 3.1, 3.2.
Projection
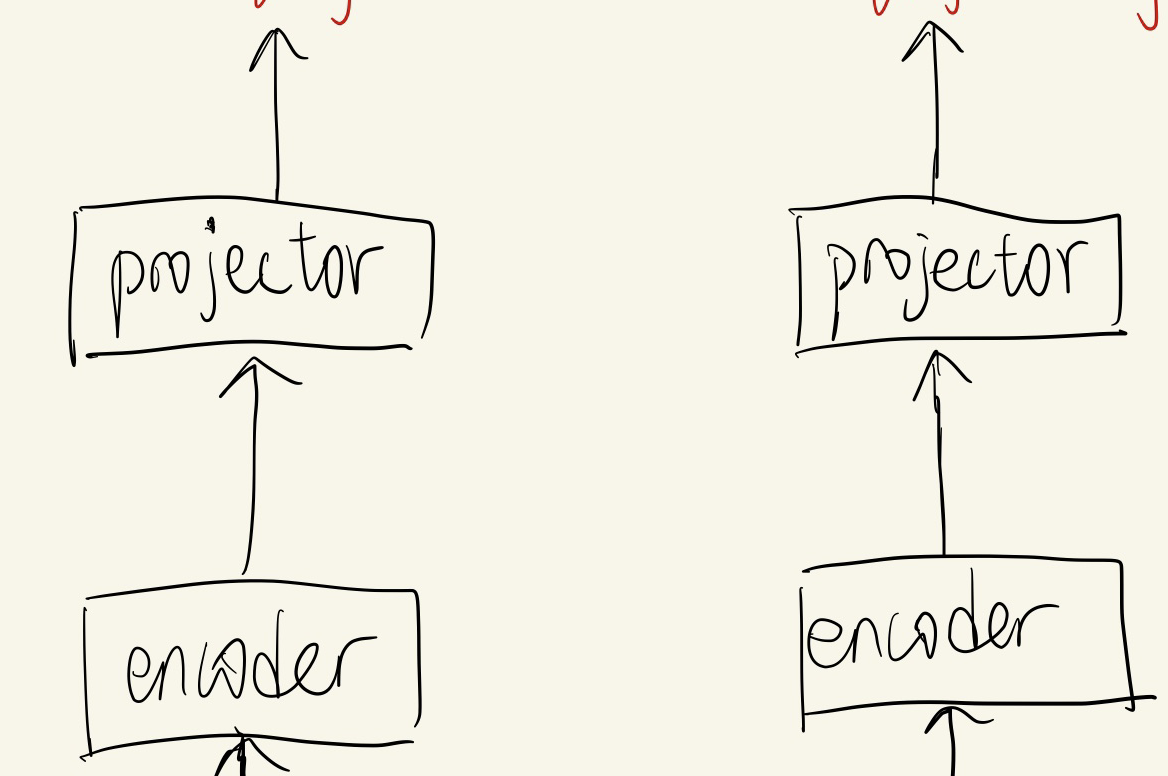
Projection is just a single dense layer with ReLu and is used bewteen the output of encoder and the input of loss function. It can make the outputs of encoder smoother. The experiment results show that add a nonlinear projector(one dense layer + Relu) improves accuracy a lot.
We observe that a nonlinear projection is better than a linear projection (+3%), and much better than no projection (>10%).
Another interesting result is that:
Furthermore, even when nonlinear projection is used, the layer before the projection head, h, is still much better (>10%) than the layer after, z = g(h), which shows that the hidden layer before the projection head is a better representation than the layer after.
which means that projection is really usefull for contrastive learning.
Hyperparameters
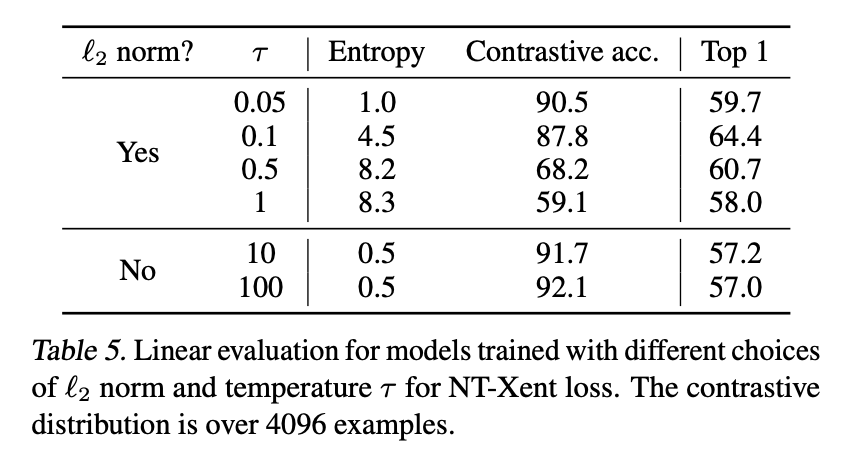
Table 5 shows that temperature \(\tau\) has a strong effect on accuracy. Also, if model is trained without l2 norm, it may overfit (much higher in contrastive acc but low acc in downstream tasks).
In conclusion, this part talks more about tricks. It proves that \(\tau\) is an important hyper parameter and l2 norm help representation learning.
Actually, this chapter in the paper also describes about the loss function. But I decided to dedicate a specialized article for all loss functions in contrastive learning. We will talk it in that article.
Huge negative samples
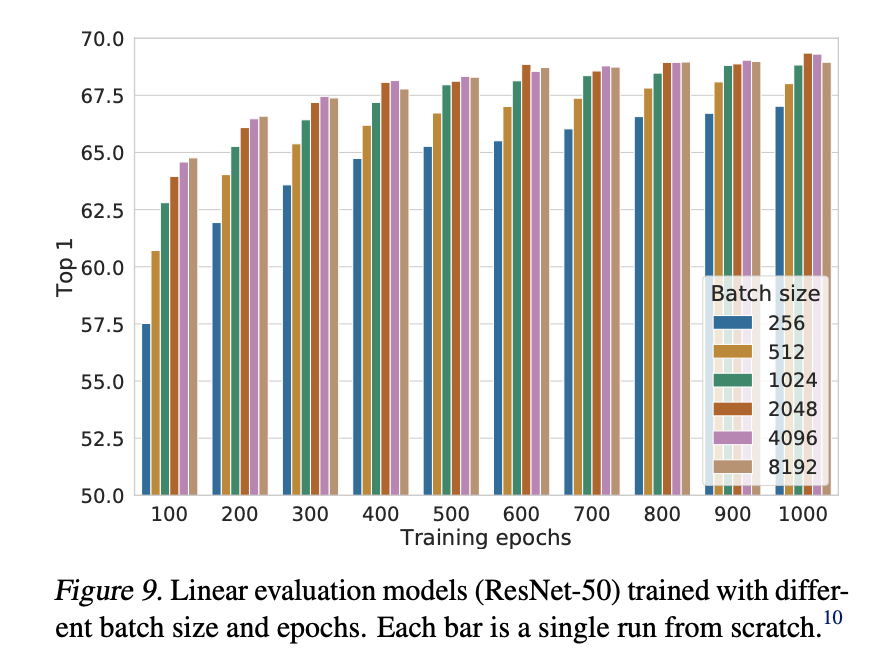
Figure 9 shows that the accuracy of simCLR increases significantly with the increase of batch size. Since the size of batch size is the size of negative samples, the paper says that a huge negative sample set is the key to improving the performance of contrastive learning.
However, if you use a batch size which is more than 1024 to train, it requires huge calculation recourses and many tricks to make it start training. Hence, simCLR is hard to preproduce by ourselves and hard to land in real scene.
Conclusion
Although simCLR almost can not be preproduced and landed, it proves many useful tricks and insights for contrastive learning. Hence, simCLR has a huge impact on follow-up research due to its easy framework and strong results.