This article aims to introduce a new kind of framework in contrastive learning which does not use negative samples.
Paper: Chen, X., & He, K. (2021). Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 15750-15758). Updated version accessed at: https://arxiv.org/abs/2011.10566
Novelty
Simsiam is not the first framework which does not use negative samples. BYOL (Grill, J. B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., ... & Valko, M. (2020). Bootstrap your own latent-a new approach to self-supervised learning. Advances in Neural Information Processing Systems, 33, 21271-21284.) is early than it and has already achieved better accuracy on ImageNet. Generally, SimSiam is just a special case of BYOL. But SimSiam’s beautiful subtraction of BYOL makes people realize the essence of success in contrastive learning without negative samples.
Note
Simsiam does very detailed ablation experiments about its used techniques like: stop-gradient, predictor, hypothesis, loss function, batch normalization. If you want to check result plots, I highly recommend reading the original paper and I will not put them in this blog again.
Framework
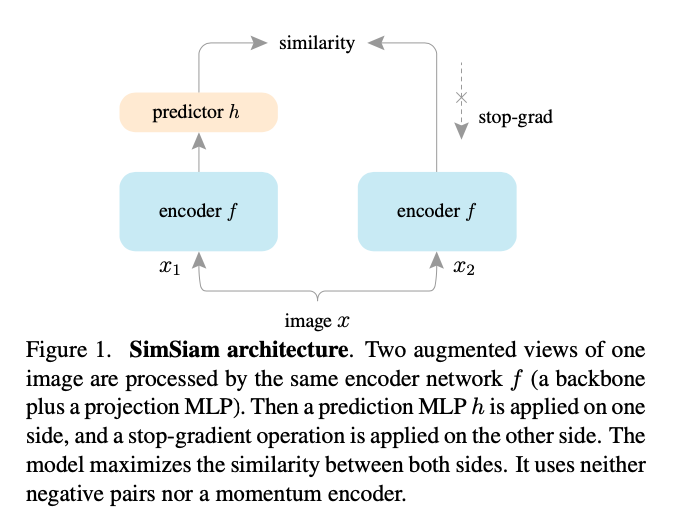
Just like paper’s name, it is a real simple framework. Model only use a same encoder(encoder + projector) and a predictor.
Predictor is new one which does not decrible in previous article. A predictor is just an extra MLP. Simsiam wants to make the feature from predictor from \(x_1\) (augmentation from image x) can be similar with \(x_2\). Hence, its loss function is just cosine similarity.
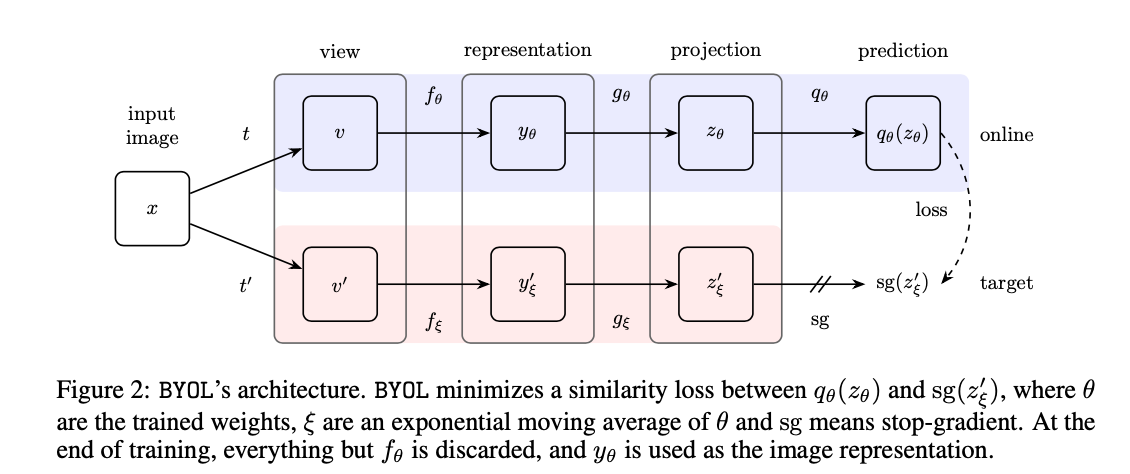
Figure 2 is BYOL’s architecture. You can see Simsiam is totally same as BYOL, which the only difference is that BYOL uses a Momentum Encoder \(y_{\xi}^{\prime}\) , where \(\xi \leftarrow \tau \xi+(1-\tau) \theta\)
Hence, you can think of SimSiam as just a special case of BYOL when \(\gamma = 1\).
This architecture is very easy to think of, but why was it not first proposed by BYOL until 2020? The biggest problem with training methods without negative samples is that the model will quickly find a shortcut and cause model collapsing. Imagine that our encoder only needs to learn to output 0 at this time, the cosine similarity of the loss function is equal to 0, and the model will no longer be updated.
How BYOL and SimSiam solve model collapsing? They both use a trick: stop gradient. We will discuss in detail in the following chapter.
Loss Function
\[\mathcal{D}\left(p_{1}, z_{2}\right)=-\frac{p_{1}}{\left\|p_{1}\right\|_{2}} \cdot \frac{z_{2}}{\left\|z_{2}\right\|_{2}}\]
Denote that the encoder is \(f\), prediction is \(h\), then we have \(p = h(f(x))\), \(z = f(x)\)
So the equation is just the cosince similarity of the features between encoder and prediction.
\[\mathcal{L}=\frac{1}{2} \mathcal{D}\left(p_{1}, z_{2}\right)+\frac{1}{2} \mathcal{D}\left(p_{2}, z_{1}\right)\]
SimSiam define a summetrized loss like above, where \(1, 2\) is the index of two augmentation images from the same image.
Stop Gradient
Stop Gradient means that when the model start to do gradient decent, the branch with stop-gradient will be treated as a constant. Hence, the loss function also can be seen as: \[\mathcal{L}=\frac{1}{2} \mathcal{D}\left(p_{1}, \text { stopgrad }\left(z_{2}\right)\right)+\frac{1}{2} \mathcal{D}\left(p_{2}, \text { stopgrad }\left(z_{1}\right)\right)\]
SimSiam has proved that stop-gradient is the key which prevents model from collapsing solutions with every detailed experiments. You can read them in the paper about experiments and results.
Authors’ hypothesis is that:
SimSiam is an implementation of an Expectation-Maximization (EM) like algorithm.
The loss function can be like:
\[\mathcal{L}(\theta, \eta)=\mathbb{E}_{x, \mathcal{T}}\left[\left\|\mathcal{F}_{\theta}(\mathcal{T}(x))-\eta_{x}\right\|_{2}^{2}\right]\]
I think that what paper writes is very clear and I could not simplify any more:

Than, we can use SGD to solve (7) and get new \(\eta_{x}\) by the updated encoder \(\mathcal{F}\).
For the prediction and the complete hypothesis, I highly recommend reading the original paper since I could not simplify them more.
Comparision
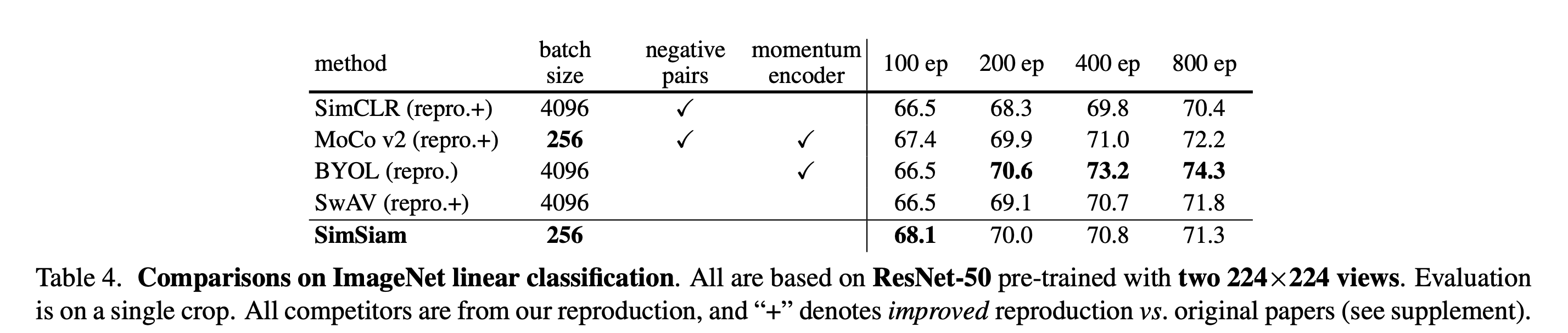
Table 4 is a global table where hasall networks we talked about in the previous chapters. And it clearly showes that SimSiam uses the simplest framework (no negative pair, no momentum encoder, very samll batch size) achieves a good result(68.1% acc) on ImageNet.
Hence, although SimSiam does not have any new techniques, it probably shows the kernel of unsupervised learning in the image domain. Such beautiful subtraction operations and exhaustive experimental evidence earned this work the Best Paper Honorable Mentions of CVPR 2022.